Конвертировать отсканированные документы и изображения в редактируемые форматы Word, Pdf, Excel и текстовые файлы
Перетащите файл сюда
Выберите файл
View all
Как распознать текст?
шаг 1
Загрузить файл
Выберите файл, который вы хотите конвертировать с вашего компьютера, Google Drive, Dropbox или перетащите его на страницу
шаг 2
Выбрать язык и выходной формат
шаг 3
Преобразование и скачивание
Нажмите кнопку «Распознать» и затем скачайте файл с распознанным текстом
Распознавание текста
Оптическое распознавание символов или оптическое считывание символов (OCR) — это электронное или механическое преобразование изображений набранного, рукописного или печатного текста в машинно-кодированный текст, будь то отсканированный документ, фотография документа, фотография сцены (например, текст на вывесках и рекламных щитах в альбомной фотографии) или текст субтитров, наложенный на изображение (например, из телевизионной трансляции). Широко используемый в качестве формы ввода данных из печатных бумажных записей данных — будь то паспортные документы, счета-фактуры, банковские выписки, компьютеризированные квитанции, визитные карточки, почта, распечатки статических данных или любая подходящая документация — это распространенный метод оцифровки печатных текстов, чтобы их можно было редактировать в электронном виде, искать, хранить более компактно, отображать в режиме онлайн и использовать в машинных процессах, таких как когнитивные вычисления, машинный перевод, преобразование текста в речь, ключевые данные и интеллектуальный анализ текста.
OCR — это область исследований в области распознавания образов, искусственного интеллекта и компьютерного зрения. Ранние версии должны были быть обучены изображениям каждого символа и работать над одним шрифтом за один раз. В настоящее время широко распространены передовые системы, способные обеспечить высокую степень точности распознавания большинства шрифтов, а также с поддержкой различных входных форматов файлов цифровых изображений. Некоторые системы способны воспроизводить форматированный вывод, который близко приближается к исходной странице, включая изображения, столбцы и другие нетекстовые компоненты.
Лучшие бесплатные OCR-сервисы для распознавания и конвертации PDF
Привет всем! Я расскажу о сервисах для распознавания текста или OCR. Считайте это небольшим рейтингом лучших OCR-утилит.

Оптическое распознавание символов (OCR — Optical Character Recognition) — механизм электронного или механического конвертирования изображения или печатного текста, например, с отсканированного документа, фотографии и т.д.
Я испытаю следующие программы и сервисы:
- PDF — Adobe Acrobat Pro — эталон всех распознавателей.
- PDF24 tools — богатый инструментарий для работы с PDF-документами, включает OCR.
- NewOCR — заявляют себя как сервис конвертации в текст форматов: JPEG, PNG, GIF, BMP, TIFF, PDF, DjVu.
- Img2txt — сервис отличается красивым интерфейсом, но спасёт ли его это?
- Free Online OCR — простецкий онлайн-сервис для распознавания.
Чтобы результат был наглядным и достоверным, нужно протестировать. Для этого я подготовил специальные документы:
- Фрагмент статьи “8 бесплатных аналогов платных программ для переводчиков”. Текст был написан в ворде, затем переведён в PDF. Сложность может представлять надпись нестандартным шрифтом, мелкие буквы, а также текст на эмблеме, но в целом документ простой и имеет текстовый слой.
- Тот же фрагмент, но без текстового слоя — скрин, завёрнутый в PDF. Базовые сложности те же, только к ним ещё добавляется необходимость распознавания всего остального текста и необходимость сохранить форматирование.
- Рекламная брошюра масел. Сложное и разное форматирование, местами текстовый слой есть, местами его нет. Отнюдь не простой документ. Посмотрим, справятся ли конкурсанты.
Adobe Acrobat Pro
Я попробую сравнить качество распознавания при конвертировании в редактируемый формат между бесплатными сервисами и эталоном — Adobe Acrobat DC.
Adobe Acrobat DC идёт первым как эталон, созданный для одной задачи — для работы с pdf-файлами.
Простой файл с текстовым слоем:

Ожидаемо. Никаких трудностей. Полная конвертация в редактируемый формат. Изображение по центре осталось нетронутым, но это невеликая проблема, можно подписать или обработать в Paint.
Простой файл без текстового слоя:

Нестандартный шрифт не распознался, но мелкий шрифт под звёздочкой распознался достаточно хорошо. Ещё пару букв пропустил, но допустимая погрешность для последующего ручного редактирования.
Сложный файл с непостоянным текстовым слоем:

Как сказать. Результат ожидаемо плохой, потому что файл очень сложный. Впрочем, отредактировать всё равно можно, лучше, чем ничего.
Почему я не взял на тест больше программ для ПК? А их нет. Существует несколько простых программ, которые распознают только изображения или устанавливают на компьютер мусор. Я пробовал: Free OCR, Simple OCR, CuneiForm OCR, Freemore OCR. Вторая категория — это титаны вроде Abbyy или Adobe, которых мы стараемся избежать в этой статье.
Итак, перейдём к онлайн-сервисам.
PDF24 tools
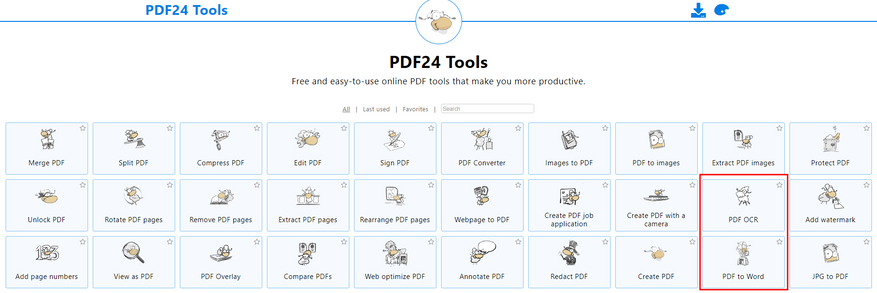
PDF24 tools — многогранный сервис. Он может распознать текст в PDF, но в результате всё равно выдаст PDF. На наше счастье среди утилит этого сайта есть и конвертер в Word. Они даже расположены рядом.
Простой файл с текстовым слоем:

Получилось очень плохо, но текст типа сохранён полностью. Изображение вырезано и половина страницы пустая. Ладно, сочтём, что так и должно быть.
Простой файл без текстового слоя:
С задачей сервис не справился. После распознавания и конвертации в ворд, я увидел пустой лист.
Сложный файл с непостоянным текстовым слоем:
Результат оказался таким же — пустой лист. Но сервис предлагает три режима конвертации:
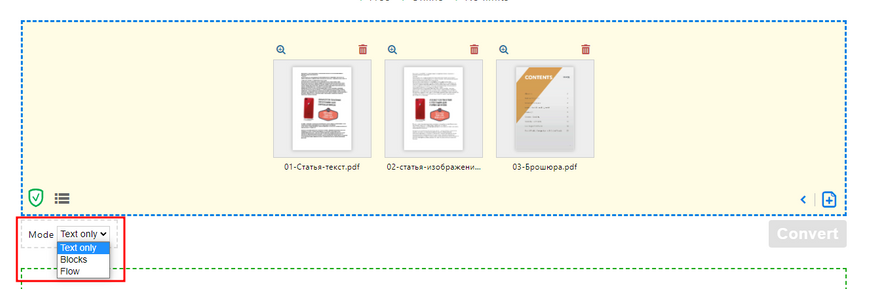
Я попробовал все три, лучший результат выдал третий режим "только текст":

Распознался даже сложный шрифт!
Брошюра тоже распозналась, но легче мне от этого не стало:

Спорный сервис. Конвертирует и распознаёт быстро и удобно, много разных утилит. Пусть будет, конечно, на крайняк покатит.
NewOCR
NewOCR — нашёл в одной из статей про лучшие сервисы распознавания символов на просторах интернета. Говорят, что сервис хороший.
Простой файл с текстовым слоем:
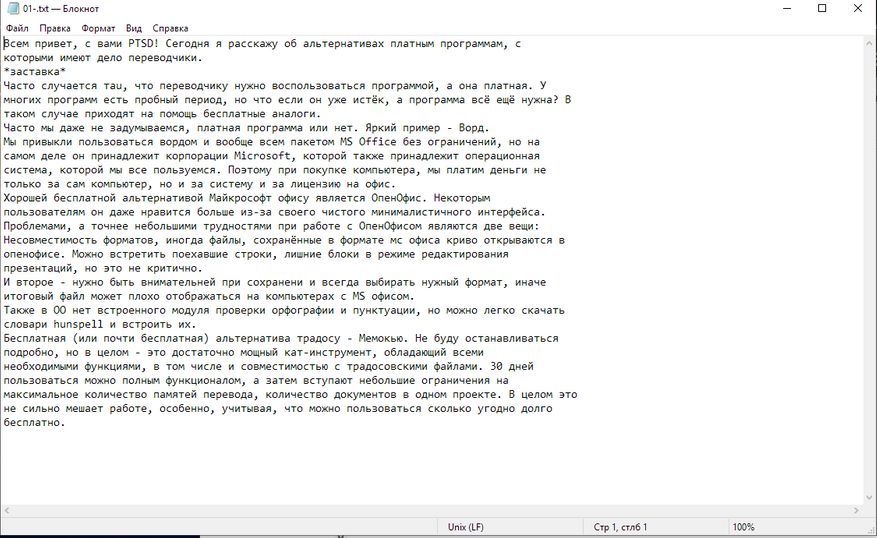
Текст распозанёт хорошо, но предлагает выбрать только формат .txt, не распознаёт картинку и даже не пытается сохранить форматирование.
Простой файл без текстового слоя:

Неплохо распознал основной язык — русский, но ужасно справился с английским. Вся латиница превратилась в какую-то кашу. С другой стороны распознать получилось даже нестандартный шрифт с картинки. Не без ошибок, нор всё же. А ещё удалось получить формат Word.
От чего это зависит — не знаю.
Сложный файл с непостоянным текстовым слоем:
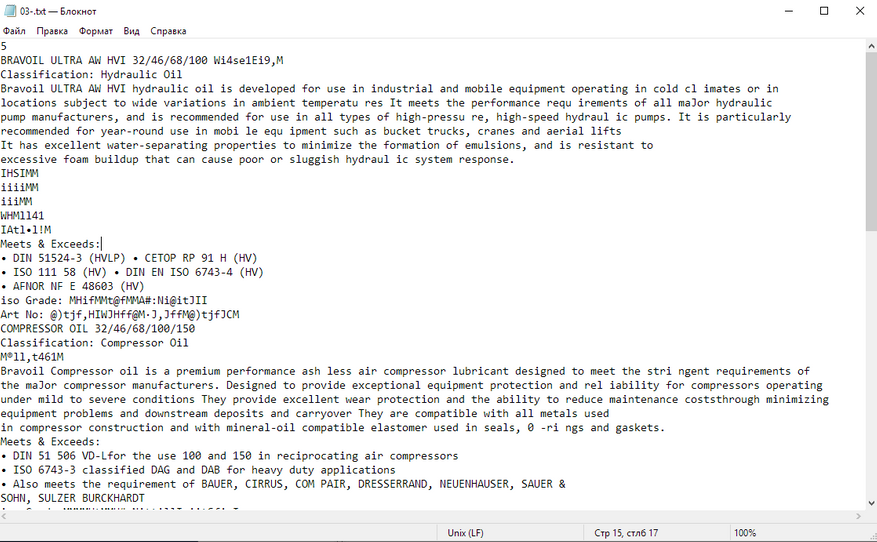
Брошюра тоже распозналась косячно. Вместо многих символов ужасные кракозябры, слова собрались в кашу, формат только .txt. Зачем мне нужно вот это? Легче отредактировать скриншоты в paint, чем так.
Сервис неплохо справляется с распознаванием текста, но что-нибудь сложнее, чем абзацы текста ему не под силу. Если в тексте встречается несколько языков, то один из них обязательно будет воспринят неправильно. Даже если указать два языка в поле перед распознанием. Про форматирование можно забыть, его здесь не будет.
А ещё мне не понравилось, что каждую страницу многостраничного документа придётся распознавать и скачивать отдельно. Документ на 50 страниц? Простите, но придётся выкачивать по одной странице за раз. А ещё придётся подождать 5 секунд перед распознанием очередной страницы. Не больше ни меньше.
Если попытаетесь распознать быстрее, получите ошибку. А ещё не всегда с первого раза точно прицеливается в страницу, иногда выхватывает маленький фрагмент страницы и пытается его распознать.
Img2txt
Сервис Img2txt. Нашёл его где-то на просторах интернета в комментариях к статье о лучших сервисах.
Простой файл с текстовым слоем:
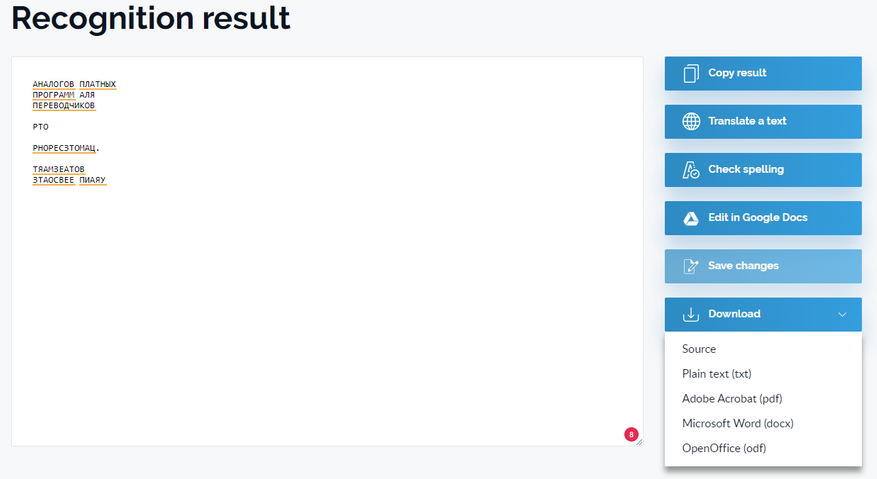
Крупный текст распознал, мелкий превратил в кашу. Решил, забить на текстовый слой и распознал только картинку. Странное решение. Зато предлагает много форматов.
Простой файл без текстового слоя:
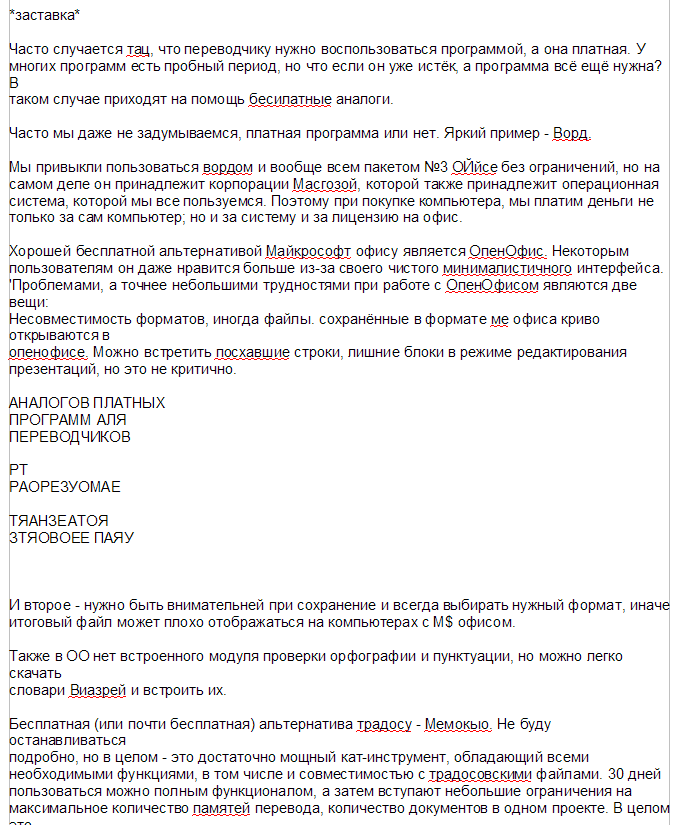
Не сказать, что плохо, но и не сказать, что хорошо. Некоторые буквы перепутал, латиницу не распознал. Но по крайней мере можно скачать в вордовском формате.
Сложный файл с непостоянным текстовым слоем:
Куцый результат. Распозналось плохо, большая часть текста пропущена, слова в кашу превратились. Получилась бесполезная белиберда.
Ещё один сервис, который распознаёт неплохо простые документы с большими абзацами текста. Раздражает, что сначала нужно загрузить файл, выбрать для него язык, потом файл обработается сервером, нужно снова выбрать для него язык и запустить распознавание. Я как-то ожидал, что загружая я уже достаточно чётко выражаю намерение распознать файл.
Ещё одна беда — это постраничное распознавание. Как и в случае с NewOCR каждая страница распознаётся отдельно, скачивается отдельным документом. Только тут ещё необходимо для каждой новой страницы повторно выбирать язык.
А ещё это единственный сервис с ограничением размера файла. Максимум — 8 мб.
Online OCR
Online OCR — сервис с самым непримечательным названием. Я упоминал этот сервис в статье про 8 бесплатных аналогов платных программ.
Простой файл с текстовым слоем:

Ого. Результат удивляет. Почти идеальный. Мало того, что распознание прошло почти мгновенно, так ещё и латиница распозналась там, где надо. Даже мои опечатки были распознаны правильно. То что текст вокруг картинки — это ерунда.
Чуть-чуть не дотянул до уровня Adobe.
Простой файл без текстового слоя:

Снова в яблочко! В этот раз побольше промахов, но результат достойный. Хотя бы картинка сохранилась и часть мелкого текста с неё удалось распознать.
Сложный файл с непостоянным текстовым слоем:

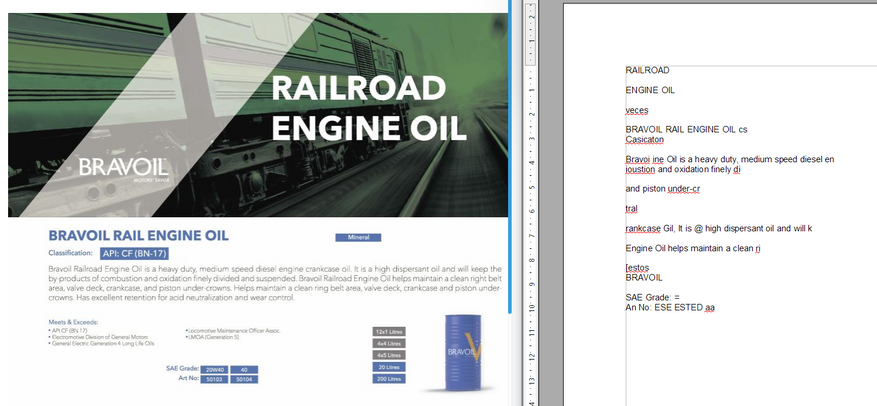
Ух ты! Сервис справился с распознаванием и этого документа! Удивительно, но факт. Есть некоторые недочёты, но это очень хороший результат. С редактированием такого файла в ворде придётся очень сильно помучиться, зато распознаны все таблички, большинство надписей.
Если в ваши обязанности не входит вёрстка, то это именно то, что нужно.
Я бы назвал это самым большим успехом. Даже Adobe по сравнению с этим меркнет:

Это лучший сервис! К сожалению, без регистрации он не даст распознать PDF больше 15 страниц, большие изображения, ZIP-архивы и ещё что-то. Но после регистрации сервис даёт только 50 бесплатных страниц.
Я слышу слово "абьюз" или мне кажется? Раскрою секрет, как сделать сервис абсолютно бесплатным. Создатели сайта не придумали подтверждение почты при регистрации. Можно указать любой вымышленный адрес. Как только заканчиваются страницы, переезжаем на новый аккаунт и пользуемся 50 бесплатными.
Забавно получается.
Читайте другие статьи переводческого цикла: