4 способа распознать текст с ПДФ документа: на скане, фотографии или изображении



✅ Главная Обучение Как распознать текст с PDF
Хотите распознать текст в электронном документе?Воспользуйтесь программой PDF Commander!
PDF Commander — универсальный софт с функцией распознавания текста с ПДФ. Программа выбрана экспертами, которые протестировали эту возможность. Результаты обработки и инструкции найдете ниже в статье. Также доступны инструменты для редактирования: выделение цветом, добавление гиперссылок, размытие конфиденциальных данных и другие.

Технология OCR (optical character recognition) выполняет оптическое распознавание символов. С ее помощью книги и документация переводятся в электронный вид. Обработанный материал можно копировать и делать по нему поиск. Это значительно упрощает документооборот в организациях, работу образовательных учреждений и многих других сфер.
В статье расскажем, в каких случаях функция доступна OCR, а также поэтапно разберем, как распознать текст в ПДФ файле в приложении на ПК.
Ознакомьтесь с видеоуроком, чтобы узнать, как распознать текст в файле:

Как распознать текст в PDF файле?
Технология OCR полезна как для работы, так и для учебы. Копирование информации для конспекта из отсканированного учебника займет с ней 2-3 минуты — не придется перепечатывать страницы вручную. Существует несколько типов объектов, в которых получится распознать символы: сканы, фото и картинки. Есть выбор русского или английского языка. Также пользователю доступно внесение изменений в файл, например можно исправить ошибки (с помощью функций «Скрыть область» и «Текст»).
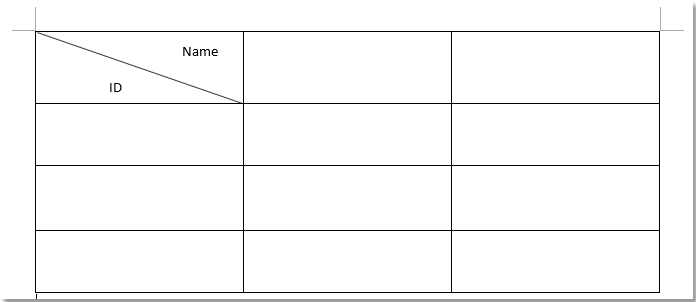
В документе после сканирования
Сканы старых книг и длинные отчеты — плохой материал для обработки из-за объема и выцветшей от времени бумаги. PDF Commander способен успешно справиться с распознаванием текста с ПДФ, но стоит учесть несколько советов, чтобы все точно получилось. Инструкция:
- 1.Отсканируйте бумаги или откройте готовый файл в программе PDF Commander (нажмите «Открыть PDF»). В верхнем меню на вкладке «Редактор» выберите «Распознать текст».
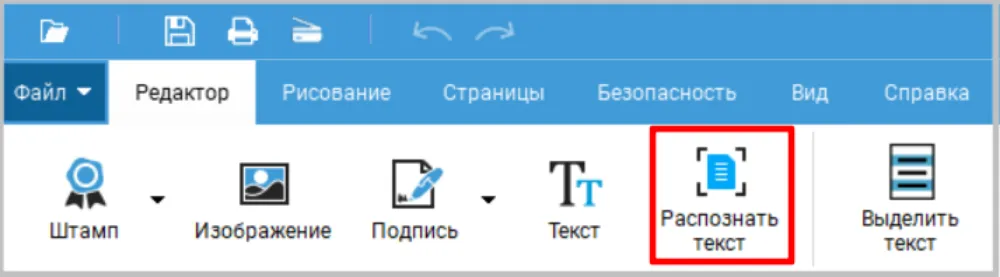
- Если документ объемный, на обработку потребуется несколько минут. Можете указать страницы нужного раздела для ускорения процесса.
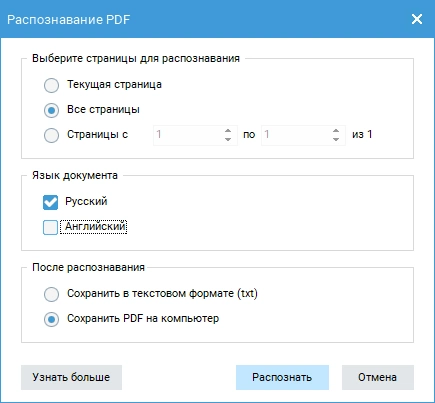
- Выберите русский язык. Результат сохраните в ПДФ или как TXT-файл.
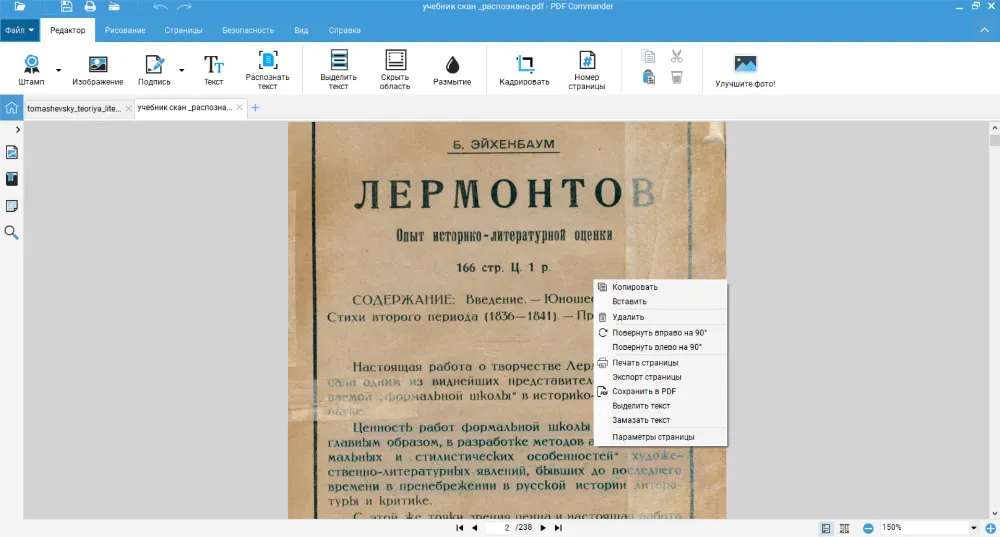
При подготовке учебных заданий важно не только распознать текст PDF, но и структурировать материал. Выделите цветом ключевые места конспекта, это поможет не потерять главную мысль научной статьи и лучше запомнить информацию.
По фотографии документа
Если требуется распознать надпись, но доступа к сканеру нет, то стоит воспользоваться телефоном или фотоаппаратом. Сделайте снимок или найдите изображение в памяти телефона. Также можно скачать его из вложений диалога в мессенджере. Для успешного определения всех слов очень важно, чтобы исходное изображение было четким и ярким.
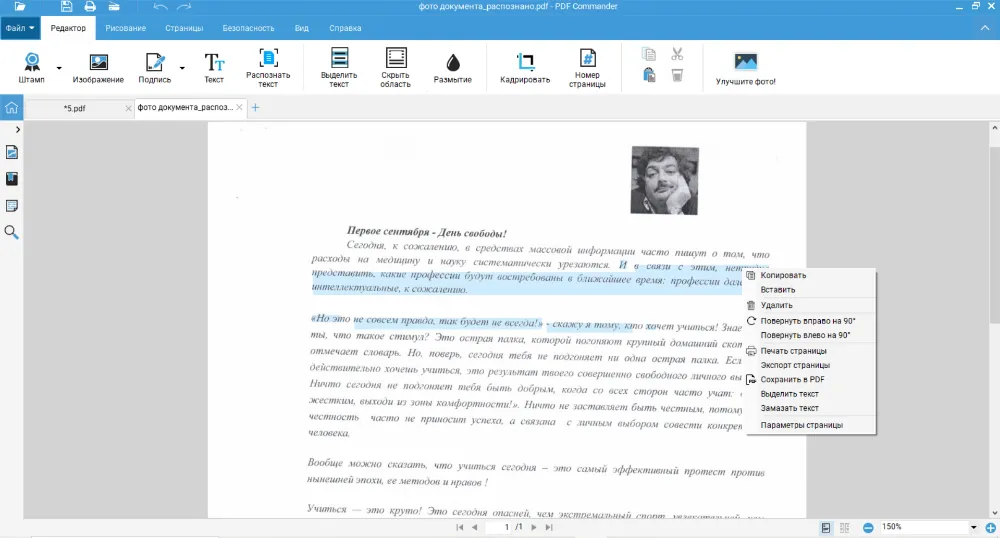
- Нажмите «Открыть PDF», выберите изображение в любом формате: PNG, JPG, GIF и другие. Во вкладке «Редактор» кликните кнопку «Распознать текст».
- Функция достаточно быстро найдет все символы. Выберите один из вариантов сохранения: новый ПДФ или в формате TXT.
Паспортные данные и номера карт можно убрать с помощью функций «Размытие» и «Скрыть область». Также можете поставить пароль на открытие и изменение. Они находятся в разделе «Безопасность».
Текст на изображении
В процессе обучения и на рабочих планерках принято сопровождать важную информацию презентациями, графиками, рисунками и схемами. Эти материалы стоит сохранять на случай, если они понадобятся в дальнейшем. Лучше всего для этого использовать технологию OCR, ведь с помощью нее можно быстро и удобно копировать надписи.
Функцией можно Воспользоваться в случае, если нужный учебник в интернете есть только в формате картинки. Не тратьте время на то, чтобы перепечатать текст — в программе можно конвертировать изображение в PDF и применить распознавание.
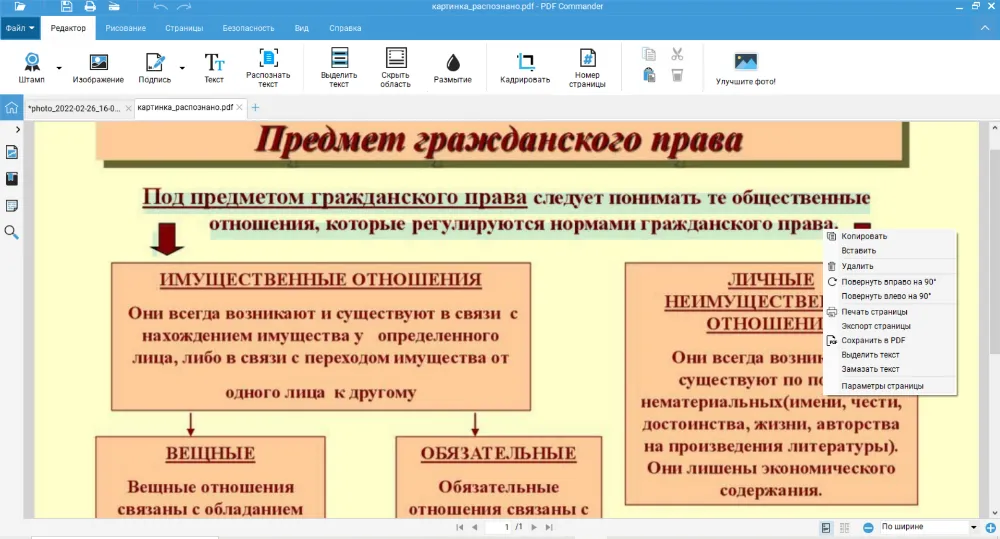
- Откройте редактор и создайте новый документ. Софт работает со множеством графических форматов, поэтому предварительно конвертировать ничего не требуется. Если нужно распознать символы из картинок с презентации, то необходимо сначала подготовить скриншоты, а после загрузить их в PDF Commander.
- На вкладке «Редактор» кликните «Распознать текст».
- Немного подождите, пока программа найдет все символы. На слайдах,схемах и графиках может быть много информационных блоков с разным оформлением. Это привлекает внимание аудитории, но для программы определить, в каком порядке все следует — сложная задача. Выделяйте каждый элементов отдельно, чтобы расположить их в логичном порядке.
- Сохраните документ в удобном формате.
Следует выбирать картинки в хорошем качестве. Если даже пользователь с трудом может прочитать информацию, то шанс успешного анализа сервисом невысок. Символы не должны сливаться с другими объектами. Важно проверить, не накладываются ли элементы друг на друга.
Что делать, если файл на английском языке
Распознать текст с PDF будет удобно как для взаимодействия с рабочей документацией на иностранном языке, так и для обучения английскому. Функция позволяет быстро скопировать слово или выражение и найти перевод.
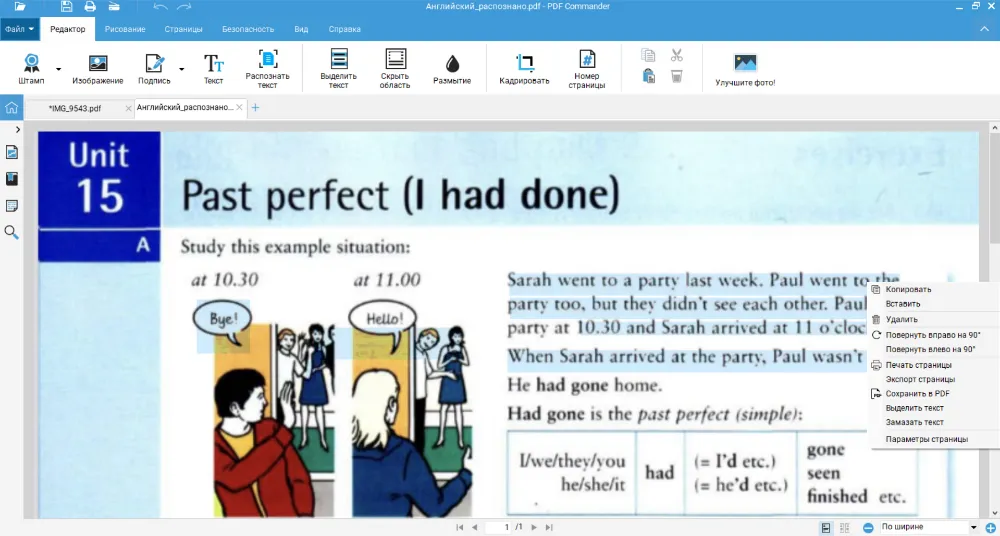
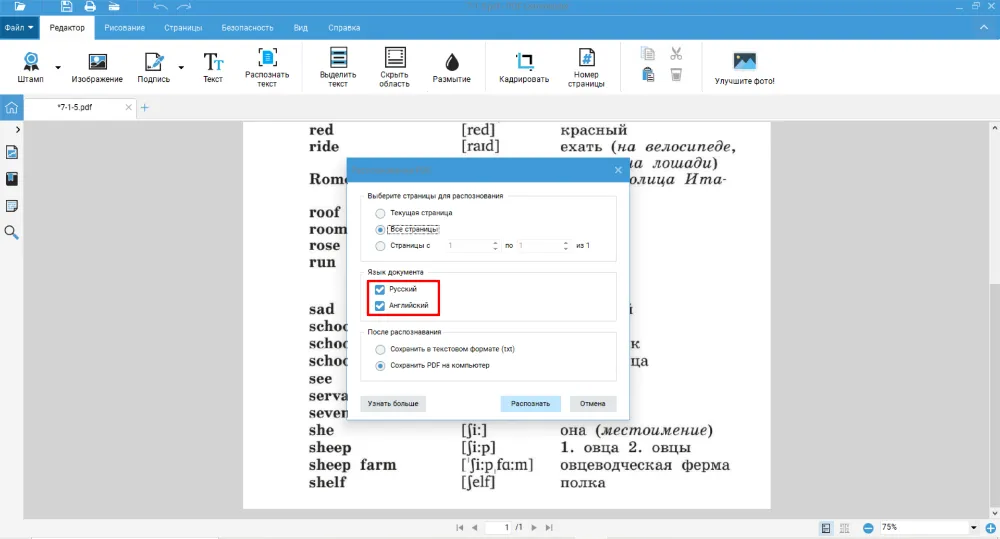
- Нажмите «Открыть PDF» и выберите документ или изображение. Кликните по кнопке «Распознать текст» и перейдите к настройкам.
- Обязательно отметьте английский как язык документа. Если обрабатываете учебное пособие, то не забудьте выбрать номера страниц, чтобы долго не ждать.
- Останется сохранить итог. Преобразуйте его в TXT или создайте новый ПДФ.
Можно выбрать оба языка — русский и английский. Например, если в учебнике есть словарь с переводом, при распознавании символов нужно учесть и это.
В профессиональной деятельности чаще всего приходится прибегать к использованию данной функции переводчикам. Если нужно адаптировать американский комикс для читателей из России, достаточно соединить сохраненный текст и страницы.
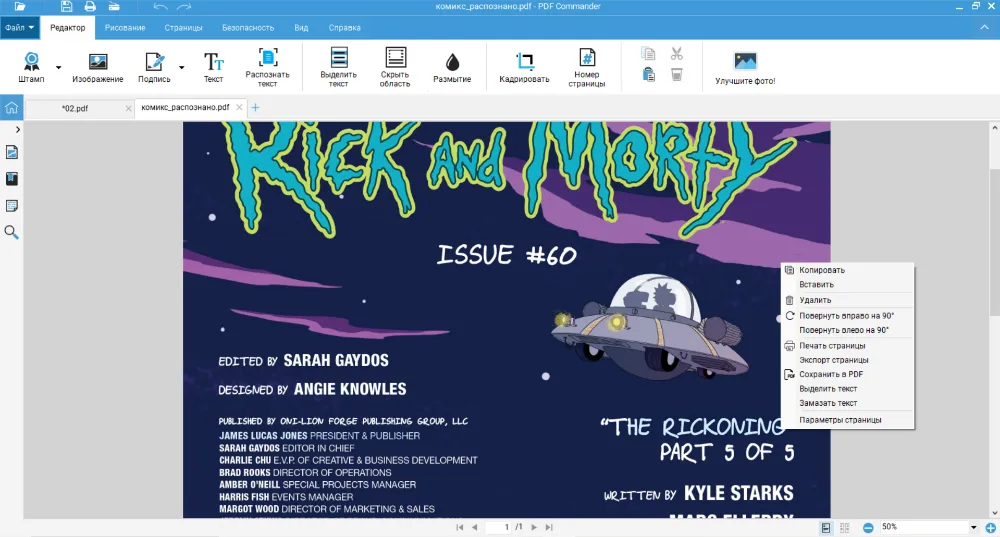
Также PDF Commander подойдет тем, кто хочет читать комиксы, которые только вышли и не получили перевода на русский. Иногда их можно скачать бесплатно в ПДФ формате. В программе легко приближать страницы и скрывать верхнюю панель. Для перемещения используйте инструмент «Рука».
Результаты тестирования
Редактор показал себя хорошо в обработке разных типов файлов. Даже в старом учебнике, который имеет повреждения, PDF Commander смог различить символы. На выцветших страницах и в проклеенных скотчем местах программа опознала все элементы.
Хотя в программе доступна обработка сложного для восприятия материала, лучше заранее подготовить изображения, провести обработку при необходимости. Слова должны хорошо читаться, не сливаться с другими элементами (таблицами, рисунками, схемами) и друг другом. Это снижает вероятность ошибки и упрощает работу.
Часто задаваемые вопросы
OCR распознает 100% текста?
Многое зависит от качества используемого материала. Труднее всего работать со сканами старых книг: в них выцветают страницы, появляются повреждения. Иногда во время сканирования появляются засветы, текст смазывается. При обработке таких объектов могут возникнуть неточности. Если использовать изображения в хорошем качестве, где символы четкие и не сливаются, проблем, как правило, не бывает.
Как исправить ошибки в PDF после распознавания текста?
После обработки с помощью OCR PDF файла результат сохраняется как новый документ, программа автоматически откроет его во втором окне. Используйте инструменты «Скрыть область» и «Текст», чтобы исправить ошибку.
Как защитить ПДФ документ от распознавания текста?
В программу PDF Commander добавлена специальная функция для ограничения доступа. Во вкладке «Безопасность» нажмите «Установить пароль». Доступ будет только у тех пользователей, которым вы его сообщите.
Лучшие бесплатные OCR-сервисы для распознавания и конвертации PDF
Привет всем! Я расскажу о сервисах для распознавания текста или OCR. Считайте это небольшим рейтингом лучших OCR-утилит.

Оптическое распознавание символов (OCR — Optical Character Recognition) — механизм электронного или механического конвертирования изображения или печатного текста, например, с отсканированного документа, фотографии и т.д.
Я испытаю следующие программы и сервисы:
- PDF — Adobe Acrobat Pro — эталон всех распознавателей.
- PDF24 tools — богатый инструментарий для работы с PDF-документами, включает OCR.
- NewOCR — заявляют себя как сервис конвертации в текст форматов: JPEG, PNG, GIF, BMP, TIFF, PDF, DjVu.
- Img2txt — сервис отличается красивым интерфейсом, но спасёт ли его это?
- Free Online OCR — простецкий онлайн-сервис для распознавания.
Чтобы результат был наглядным и достоверным, нужно протестировать. Для этого я подготовил специальные документы:
- Фрагмент статьи “8 бесплатных аналогов платных программ для переводчиков”. Текст был написан в ворде, затем переведён в PDF. Сложность может представлять надпись нестандартным шрифтом, мелкие буквы, а также текст на эмблеме, но в целом документ простой и имеет текстовый слой.
- Тот же фрагмент, но без текстового слоя — скрин, завёрнутый в PDF. Базовые сложности те же, только к ним ещё добавляется необходимость распознавания всего остального текста и необходимость сохранить форматирование.
- Рекламная брошюра масел. Сложное и разное форматирование, местами текстовый слой есть, местами его нет. Отнюдь не простой документ. Посмотрим, справятся ли конкурсанты.
Adobe Acrobat Pro
Я попробую сравнить качество распознавания при конвертировании в редактируемый формат между бесплатными сервисами и эталоном — Adobe Acrobat DC.
Adobe Acrobat DC идёт первым как эталон, созданный для одной задачи — для работы с pdf-файлами.
Простой файл с текстовым слоем:

Ожидаемо. Никаких трудностей. Полная конвертация в редактируемый формат. Изображение по центре осталось нетронутым, но это невеликая проблема, можно подписать или обработать в Paint.
Простой файл без текстового слоя:

Нестандартный шрифт не распознался, но мелкий шрифт под звёздочкой распознался достаточно хорошо. Ещё пару букв пропустил, но допустимая погрешность для последующего ручного редактирования.
Сложный файл с непостоянным текстовым слоем:

Как сказать. Результат ожидаемо плохой, потому что файл очень сложный. Впрочем, отредактировать всё равно можно, лучше, чем ничего.
Почему я не взял на тест больше программ для ПК? А их нет. Существует несколько простых программ, которые распознают только изображения или устанавливают на компьютер мусор. Я пробовал: Free OCR, Simple OCR, CuneiForm OCR, Freemore OCR. Вторая категория — это титаны вроде Abbyy или Adobe, которых мы стараемся избежать в этой статье.
Итак, перейдём к онлайн-сервисам.
PDF24 tools
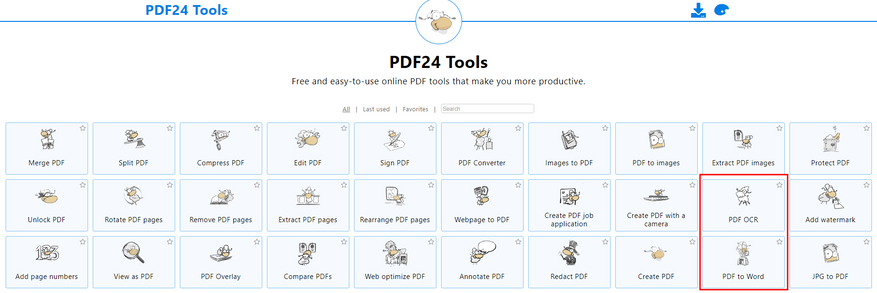
PDF24 tools — многогранный сервис. Он может распознать текст в PDF, но в результате всё равно выдаст PDF. На наше счастье среди утилит этого сайта есть и конвертер в Word. Они даже расположены рядом.
Простой файл с текстовым слоем:

Получилось очень плохо, но текст типа сохранён полностью. Изображение вырезано и половина страницы пустая. Ладно, сочтём, что так и должно быть.
Простой файл без текстового слоя:
С задачей сервис не справился. После распознавания и конвертации в ворд, я увидел пустой лист.
Сложный файл с непостоянным текстовым слоем:
Результат оказался таким же — пустой лист. Но сервис предлагает три режима конвертации:
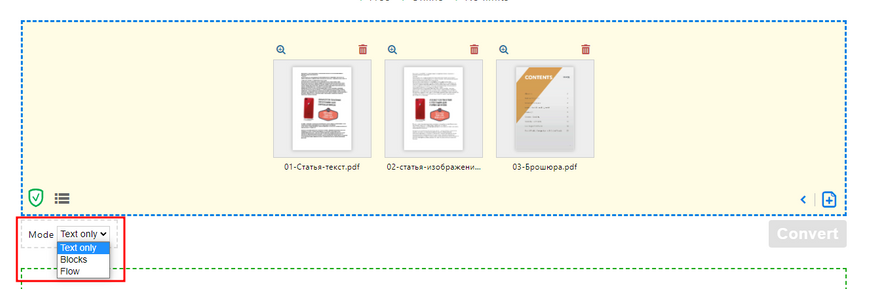
Я попробовал все три, лучший результат выдал третий режим "только текст":

Распознался даже сложный шрифт!
Брошюра тоже распозналась, но легче мне от этого не стало:

Спорный сервис. Конвертирует и распознаёт быстро и удобно, много разных утилит. Пусть будет, конечно, на крайняк покатит.
NewOCR
NewOCR — нашёл в одной из статей про лучшие сервисы распознавания символов на просторах интернета. Говорят, что сервис хороший.
Простой файл с текстовым слоем:
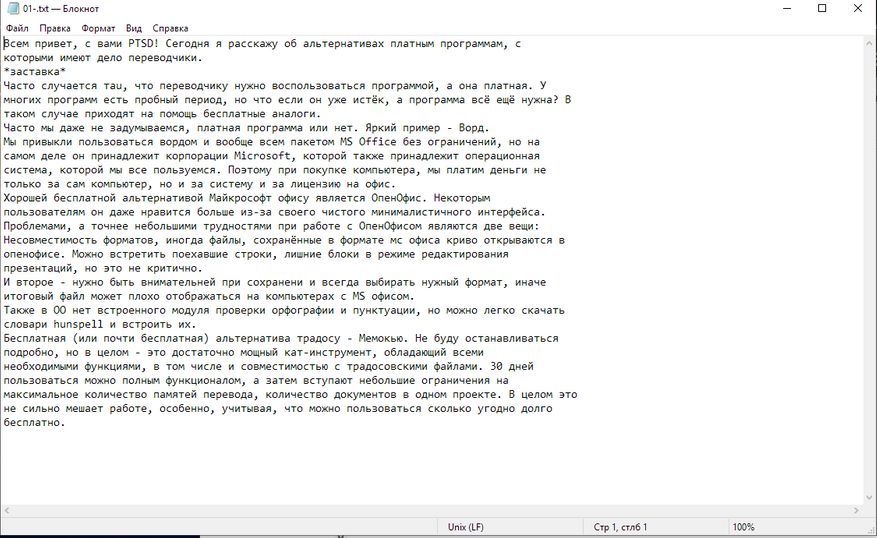
Текст распозанёт хорошо, но предлагает выбрать только формат .txt, не распознаёт картинку и даже не пытается сохранить форматирование.
Простой файл без текстового слоя:

Неплохо распознал основной язык — русский, но ужасно справился с английским. Вся латиница превратилась в какую-то кашу. С другой стороны распознать получилось даже нестандартный шрифт с картинки. Не без ошибок, нор всё же. А ещё удалось получить формат Word.
От чего это зависит — не знаю.
Сложный файл с непостоянным текстовым слоем:
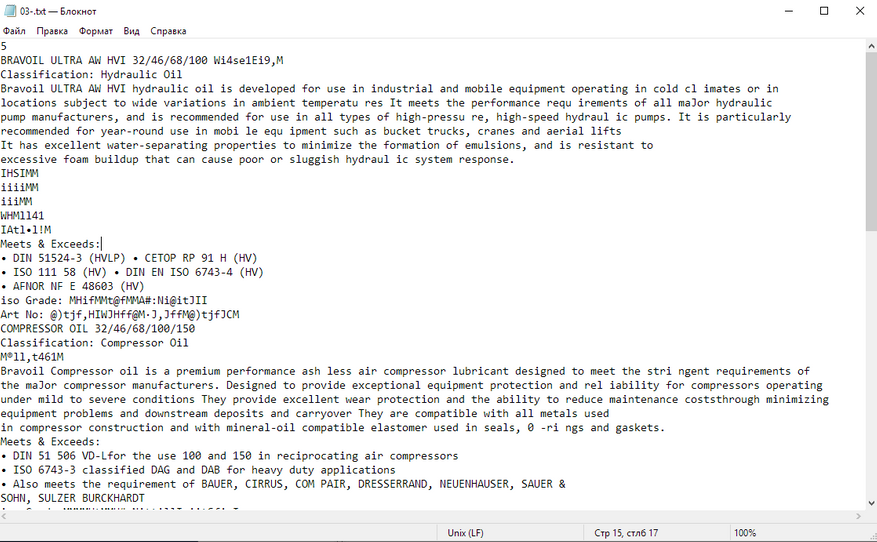
Брошюра тоже распозналась косячно. Вместо многих символов ужасные кракозябры, слова собрались в кашу, формат только .txt. Зачем мне нужно вот это? Легче отредактировать скриншоты в paint, чем так.
Сервис неплохо справляется с распознаванием текста, но что-нибудь сложнее, чем абзацы текста ему не под силу. Если в тексте встречается несколько языков, то один из них обязательно будет воспринят неправильно. Даже если указать два языка в поле перед распознанием. Про форматирование можно забыть, его здесь не будет.
А ещё мне не понравилось, что каждую страницу многостраничного документа придётся распознавать и скачивать отдельно. Документ на 50 страниц? Простите, но придётся выкачивать по одной странице за раз. А ещё придётся подождать 5 секунд перед распознанием очередной страницы. Не больше ни меньше.
Если попытаетесь распознать быстрее, получите ошибку. А ещё не всегда с первого раза точно прицеливается в страницу, иногда выхватывает маленький фрагмент страницы и пытается его распознать.
Img2txt
Сервис Img2txt. Нашёл его где-то на просторах интернета в комментариях к статье о лучших сервисах.
Простой файл с текстовым слоем:
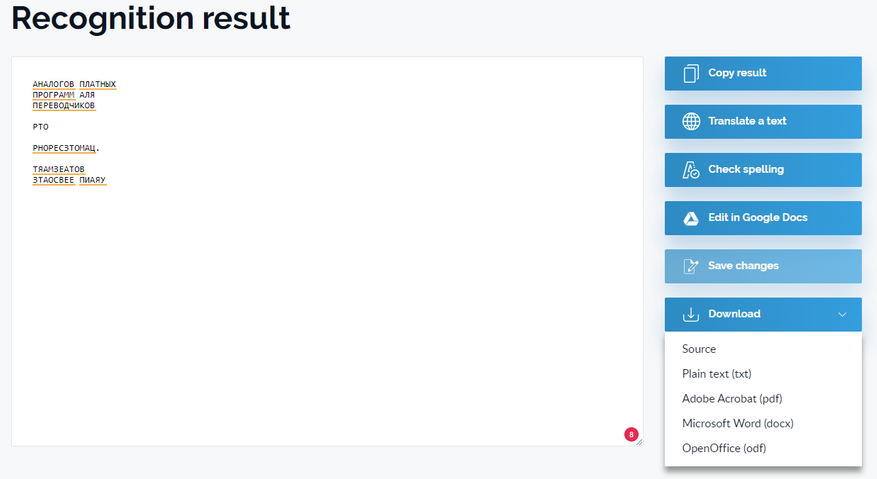
Крупный текст распознал, мелкий превратил в кашу. Решил, забить на текстовый слой и распознал только картинку. Странное решение. Зато предлагает много форматов.
Простой файл без текстового слоя:
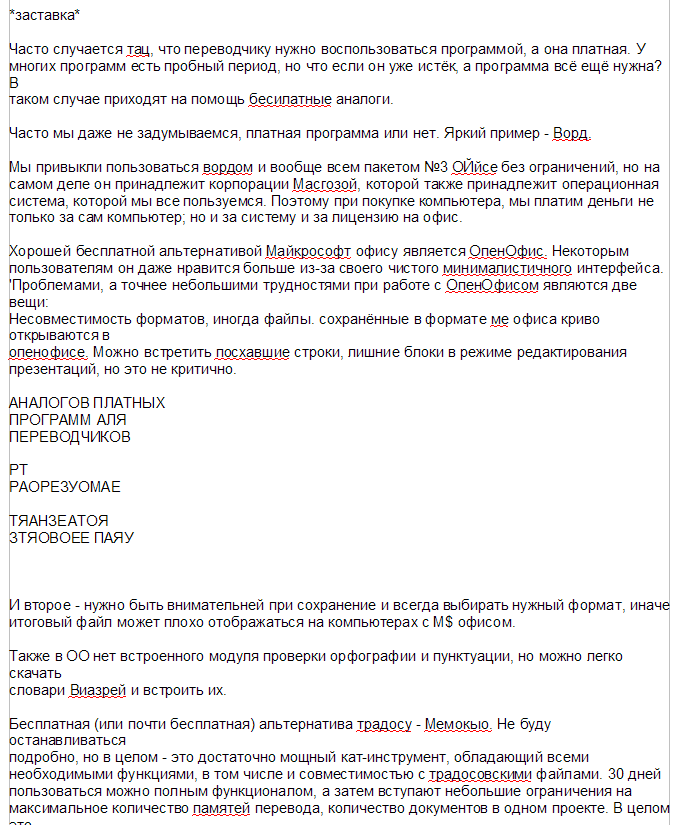
Не сказать, что плохо, но и не сказать, что хорошо. Некоторые буквы перепутал, латиницу не распознал. Но по крайней мере можно скачать в вордовском формате.
Сложный файл с непостоянным текстовым слоем:
Куцый результат. Распозналось плохо, большая часть текста пропущена, слова в кашу превратились. Получилась бесполезная белиберда.
Ещё один сервис, который распознаёт неплохо простые документы с большими абзацами текста. Раздражает, что сначала нужно загрузить файл, выбрать для него язык, потом файл обработается сервером, нужно снова выбрать для него язык и запустить распознавание. Я как-то ожидал, что загружая я уже достаточно чётко выражаю намерение распознать файл.
Ещё одна беда — это постраничное распознавание. Как и в случае с NewOCR каждая страница распознаётся отдельно, скачивается отдельным документом. Только тут ещё необходимо для каждой новой страницы повторно выбирать язык.
А ещё это единственный сервис с ограничением размера файла. Максимум — 8 мб.
Online OCR
Online OCR — сервис с самым непримечательным названием. Я упоминал этот сервис в статье про 8 бесплатных аналогов платных программ.
Простой файл с текстовым слоем:

Ого. Результат удивляет. Почти идеальный. Мало того, что распознание прошло почти мгновенно, так ещё и латиница распозналась там, где надо. Даже мои опечатки были распознаны правильно.
То что текст вокруг картинки — это ерунда. Чуть-чуть не дотянул до уровня Adobe.
Простой файл без текстового слоя:

Снова в яблочко! В этот раз побольше промахов, но результат достойный. Хотя бы картинка сохранилась и часть мелкого текста с неё удалось распознать.
Сложный файл с непостоянным текстовым слоем:

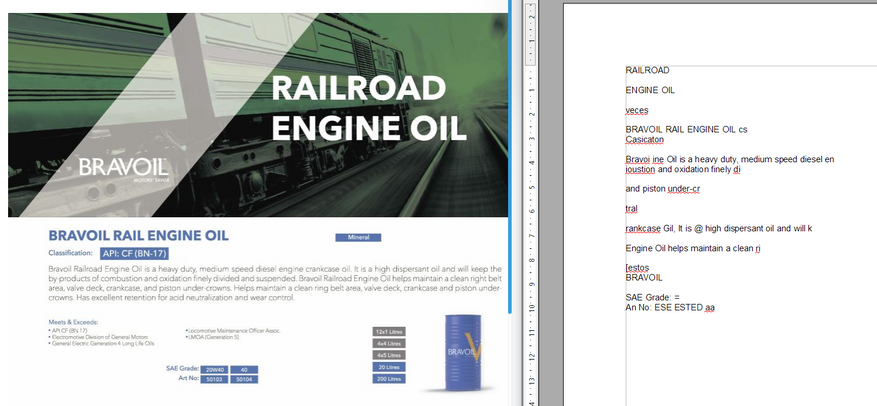
Ух ты! Сервис справился с распознаванием и этого документа! Удивительно, но факт. Есть некоторые недочёты, но это очень хороший результат. С редактированием такого файла в ворде придётся очень сильно помучиться, зато распознаны все таблички, большинство надписей.
Если в ваши обязанности не входит вёрстка, то это именно то, что нужно.
Я бы назвал это самым большим успехом. Даже Adobe по сравнению с этим меркнет:

Это лучший сервис! К сожалению, без регистрации он не даст распознать PDF больше 15 страниц, большие изображения, ZIP-архивы и ещё что-то. Но после регистрации сервис даёт только 50 бесплатных страниц.
Я слышу слово "абьюз" или мне кажется? Раскрою секрет, как сделать сервис абсолютно бесплатным. Создатели сайта не придумали подтверждение почты при регистрации. Можно указать любой вымышленный адрес. Как только заканчиваются страницы, переезжаем на новый аккаунт и пользуемся 50 бесплатными.
Забавно получается.
Читайте другие статьи переводческого цикла: