Конвертировать DOC в XML
Вы можете перевести doc документ в xml и во множество других форматов с помощью бесплатного онлайн конвертера.
Как конвертировать doc в xml?
Шаг 1
Загрузите doc-файл
Выберите файл, который вы хотите конвертировать с компьютера, Google Диска, Dropbox или перетащите его на страницу.
Шаг 2
Выберите «в xml»
Выберите xml или любой другой формат, в который вы хотите конвертировать файл (более 200 поддерживаемых форматов)
Шаг 3
Скачайте ваш xml файл
Подождите пока ваш файл сконвертируется и нажмите скачать xml-файл
Безопасность ваших файлов — наш приоритет
Понимая важность безопасности данных наших пользователей, мы реализовали ряд мер, чтобы обеспечить надежное преобразование файлов без риска утечки информации или нарушения конфиденциальности.
Шифрование данных
Вся информация, загружаемая на нашу платформу, зашифрована SSL, что обеспечивает конфиденциальность во время передачи.
Безопасное хранение
После завершения конвертации файлы хранятся на защищенных серверах в течение 24 часов и автоматически уничтожаются, исключая доступ третьих лиц.
Безобидные скрипты
Наши инструменты преобразования файлов регулярно проверяются на наличие вредоносного кода или уязвимостей, чтобы исключить риск потенциальной кибератаки.
Лучший инструмент для конвертации doc в xml
doc в xml Быстро и легко
Просто перетащите ваши файлы в формате doc на страницу, чтобы конвертировать в xml или вы можете преобразовать его в более чем 250 различных форматов файлов без регистрации, указывая электронную почту или водяной знак.
Безопасное преобразование doc в xml
Мы удаляем загруженные файлы doc мгновенно и преобразованные xml файлы через 24 часа. Все файлы передаются с использованием продвинутого шифрования SSL.
Установка программного обеспечения не требуется
Вам не нужно устанавливать какое-либо программное обеспечение. Все преобразования doc в xml происходят в облаке и не используют какие-либо ресурсы вашего компьютера.
Microsoft Word Document
Microsoft Word
OpenOffice.org Writer
IBM Lotus Symphony
Apple Pages
AbiWord
application/msword
application/kswps
Extensible Markup Language
Microsoft Visual Studio 2013
JAPISoft EditiX
Wattle XMLwriter
MacroMates TextMate
application/xml
application/x-xml
text/xml
Часто задаваемые вопросы о преобразовании doc в xml
❓ Как я могу конвертировать doc в xml?
Во-первых, выберите doc файл, который вы хотите конвертировать или перетащить его. Во-вторых, выберите xml или любой другой формат, в который вы хотите преобразовать файл. Затем нажмите кнопку конвертировать и подождите, пока файл не преобразуется
⏳ Как долго я должен ждать, чтобы преобразовать doc в xml?
Преобразование Изображение обычно занимает несколько секунд. Вы преобразовать doc в xml очень быстро.
️ Это безопасно конвертировать doc в xml на OnlineConvertFree?
Конечно! Мы удалить загруженные и преобразованные файлы, так что никто не имеет доступ к вашей информации. Все типы преобразования на OnlineConvertFree (в том числе doc в xml) 100% безопасны.
Можно ли преобразовать doc в xml без установки программного обеспечения?
Да! OnlineConvertFree не требует установки. Вы можете конвертировать любые файлы (в том числе doc в xml) онлайн на вашем компьютере или мобильном телефоне.
Создание файла XML из Word

Научитесь создавать файл XML из документа Microsoft Word для удобного обмена данными. Этот курс поможет вам улучшить навыки работы с текстовыми документами.
Формат XML предназначен для хранения данных, которые могут быть полезны в работе некоторых программ, сайтов и поддержке определенных языков разметки. Создать и открыть файл в этом формате несложно. Это можно сделать, даже если на вашем компьютере не установлено специализированное программное обеспечение.
Немного об XML
XML сам по себе является языком разметки, чем-то похожим на HTML, который используется на веб-страницах. Но если последний используется только для отображения информации и ее правильной разметки, XML позволяет структурировать ее определенным образом, что делает этот язык похожим на аналог базы данных, не требующий СУБД.
Вы можете создавать файлы XML, используя как специализированные программы, так и встроенный текстовый редактор Windows. Удобство написания кода и уровень его функциональности зависят от типа используемого программного обеспечения.
Способ 1: Visual Studio
Вместо этого редактора кода Microsoft вы можете использовать любые его аналоги от других разработчиков. Фактически, Visual Studio — это более продвинутая версия обычного Блокнота. Код теперь имеет специальную подсветку, ошибки автоматически выделяются или исправляются, а специальные шаблоны уже загружены в программу, что упрощает создание больших файлов XML.
Для начала вам необходимо создать файл. Щелкните элемент «Файл» на верхней панели и выберите «Создать…» в раскрывающемся меню. Откроется список, в котором указана запись «Файл».

Вам будет перенесено окно с выбором расширения файла, соответственно выберите пункт «XML файл».

Во вновь созданном файле уже будет первая строка с кодировкой и версией. По умолчанию записывается первая версия и кодировка UTF-8, которую вы можете изменить в любой момент. Затем, чтобы создать полный XML-файл, вам нужно записать все, что было в предыдущем операторе.
По окончании работы снова выберите в верхней панели «Файл», затем из выпадающего меню пункт «Сохранить все».
Способ 2: Microsoft Excel
Вы можете создать XML-файл без написания кода, например, используя современные версии Microsoft Excel, что позволяет сохранять таблицы с этим расширением. Однако нужно понимать, что в этом случае у вас не получится создать что-то более функциональное, чем обычный стол.
Этот метод лучше всего подходит для тех, кто не хочет или не умеет работать с кодом. Однако в этом случае пользователь может столкнуться с некоторыми проблемами при перезаписи файла в формате XML. К сожалению, преобразование обычной таблицы в XML возможно только в более новых версиях MS Excel. Для этого воспользуйтесь следующими пошаговыми инструкциями:
Способ 3: Блокнот
Даже обычный Блокнот вполне подходит для работы с XML, но у пользователя, незнакомого с синтаксисом языка, возникнут трудности, так как в нем придется писать различные команды и теги. Несколько проще и продуктивнее процесс будет в специализированных программах для редактирования кода, например, в Microsoft Visual Studio. В них есть специальные метки и подсказки, которые значительно упрощают работу человеку, не знающему синтаксиса этого языка.
Для этого метода ничего скачивать не нужно, так как в операционной системе уже есть встроенный «Блокнот». Попробуем создать простую XML-таблицу по приведенным инструкциям:
- Создайте простой текстовый документ с расширением TXT. Вы можете разместить его где угодно. Открой это.
- Начните набирать в нем первые команды.
Во-первых, вам нужно установить кодировку для всего файла и указать версию XML, это делается с помощью следующей команды: Первое значение — это версия, менять ее не нужно, а второе значение — это кодировка. Рекомендуется использовать кодировку UTF-8, так как с ней прекрасно работает большинство программ и обработчиков. Однако его можно изменить на любое другое, просто набрав желаемое имя.
- Создайте первый каталог в вашем файле, написав тег и закрыв его вот так .
- Теперь вы можете написать какой-то контент внутри этого тега. Создаем тег и даем ему любое имя, например «Иван Иванов». Готовая конструкция должна выглядеть так:
- Внутри тега теперь можно писать более подробные параметры, в данном случае это информация об определенном Иване Иванове. Мы пропишем ваш возраст и местонахождение.
- Если вы следовали инструкциям, вы должны получить тот же код, что и ниже. Когда закончите, найдите «Файл» в верхнем меню и выберите «Сохранить как…» в раскрывающемся меню. При сохранении в поле «Имя файла» после точки должно стоять расширение не TXT, а XML.

Компиляторам XML необходимо обработать этот код в виде таблицы с одним столбцом, содержащей данные о некоем Иване Иванове.
В «Блокноте» вполне можно создавать такие простые таблицы, но при создании массивов более объемных данных могут возникнуть трудности, так как в обычном «Блокноте» нет функций для иборьбы ошибок в коде или их выделения.
Как видите, в создании XML-файла нет ничего сложного. При желании его может создать любой пользователь, более-менее умеющий работать на компьютере. Однако для создания полного XML-файла рекомендуется изучить этот язык разметки, по крайней мере, на примитивном уровне.
Конвертируем doc в docx и xml на C
Продолжаю свой цикл статей, посвященный конвертации различных текстовых файлов с помощью решений, реализованных на языке C#. С момента моей последней публикации «Конвертация xls в xlsx и xml на C#» прошло более полугода, за которые я успел сменить как работодателя, так и пересмотреть свои взгляды на некоторые аспекты коммерческой разработки. Сейчас, работая в международной компании с совершенно иным подходом к разработке ПО (ревью кода, юнит-тестирование, команда автотестеров, строгое соблюдение СМК, заботливый менеджер, очаровательная HR и прочие корпоративные плюшки), я начинаю понимать, почему некоторые из комментаторов интересовались целесообразностью предлагаемых мной велокостылей, когда на рынке есть очень достойные готовые решения, например, от e-iceblue. Но давайте не забывать, что ситуации бывают разные, компании – тем более, и если потребность в решении какой-то задачи с использованием определенного инструментария возникла у одного человека, то со значительной долей вероятности она возникнет и у другого.
Итак, дано:
Поехали!
Довольно слов – давайте к делу
Установка b2xtranslator
Для работы нам понадобиться библиотека b2xtranslator. Ее можно подключить через менеджера пакетов NuGet.

Однако я настоятельно рекомендую скачать ее из официального git-репозитория по следующим причинам:
Конвертация документов строится по следующему алгоритму:
1. Инициализация дескриптора для конвертируемого файла.
StructuredStorageReader reader = new StructuredStorageReader(docPath);WordDocument doc = new WordDocument(reader);Для этого используется статический метод cs public static WordprocessingDocument Create(string fileName, OpenXmlPackage.DocumentType type) класса WordprocessingDocument . В первом аргументе указываем имя нового файла (вместе с путем), а вот во втором мы должны выбрать тип файла, который должен получиться на выходе:
WordprocessingDocument docx = WordprocessingDocument.Create(docxPath, DocumentType.Document);4. Конвертация данных из бинарного формата в формат OpenXML и их запись в объект типа WordprocessingDocument .
За выполнение указанной процедуры отвечает статический метод
public static void Convert(WordDocument doc, WordprocessingDocument docx)класса Converter , который заодно и записывает получившийся результат в файл.
Converter.Convert(doc, docx);В результате у вас должен получиться вот такой код:
using b2xtranslator.StructuredStorage.Reader; using b2xtranslator.DocFileFormat; using b2xtranslator.OpenXmlLib.WordprocessingML; using b2xtranslator.WordprocessingMLMapping; using static b2xtranslator.OpenXmlLib.OpenXmlPackage; namespace ConverterToXml.Converters < public class DocToDocx < public void ConvertToDocx(string docPath, string docxPath) < StructuredStorageReader reader = new StructuredStorageReader(docPath); WordDocument doc = new WordDocument(reader); WordprocessingDocument docx = WordprocessingDocument.Create(docxPath, DocumentType.Document); Converter.Convert(doc, docx); >> >Внимание!
Я не стал разбираться, почему так происходит, но энтузиастам могу подсказать, что причину стоит искать в 40 строчке файла «~b2xtranslatorDocWordprocessingMLMappingMainDocumentMapping.cs» в момент обработки таблицы.
Кроме того, рекомендую собирать все проекты и само решение под 64-битную платформу во избежание всяких непонятных ошибок.
Сохранение результата в поток байтов
В абстрактном классе OpenXmlPackage (см. ~b2xtranslatorCommonOpenXmlLibOpenXmlPackage.cs) давайте создадим виртуальный метод:
public virtual byte[] CloseWithoutSavingFile()
По большому счету, данный метод будет заменять собой метод Close() . Вот его исходный код:
public virtual void Close() < // serialize the package on closing var writer = new OpenXmlWriter(); writer.Open(this.FileName); this.WritePackage(writer); writer.Close(); >Скажем спасибо разработчикам библиотеки за то, что не забыли перегрузить метод Open() , который может принимать или имя файла, или поток байтов. Однако, библиотечный метод Close() , который как раз и отвечает за запись результата в файл, вызывается в методе Dispose() в классе OpenXmlPackage . Чтобы ничего лишнего не поломать и не заморачиваться с архитектурой фабрик (тем более в чужом проекте), я предлагаю просто закомментировать код внутри метода Dispose() и вызвать метод CloseWithoutSavingFile() , но уже внутри нашего метода после вызова Converter.Convert(doc, docx) .
Для сохранения результата конвертации вызываем вместо docx.Close() метод docx.CloseWithoutSavingFile() :
public MemoryStream ConvertToDocxMemoryStream(Stream stream)
Для тех, кому все-таки очень хочется получить на выходе .xml документ, еще и с сохраненной структурой, предлагаю дойти до кухни, сварить кофе покрепче, добавить в него рюмку коньяка и приготовиться к приключению на 20 минут.

Теперь, когда, казалось бы, можно воспользоваться классом-конвертором DocxToXml, работа которого была описана вот в этой статье, нас поджидает сюрприз, связанный с особенностями работы b2xtranslator.
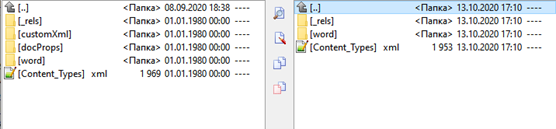
2. Внутри папки word, мы также найдем определенные отличия, перечислять которые я, конечно же, не буду:
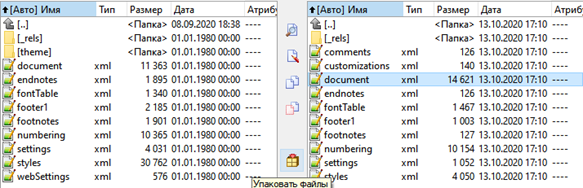
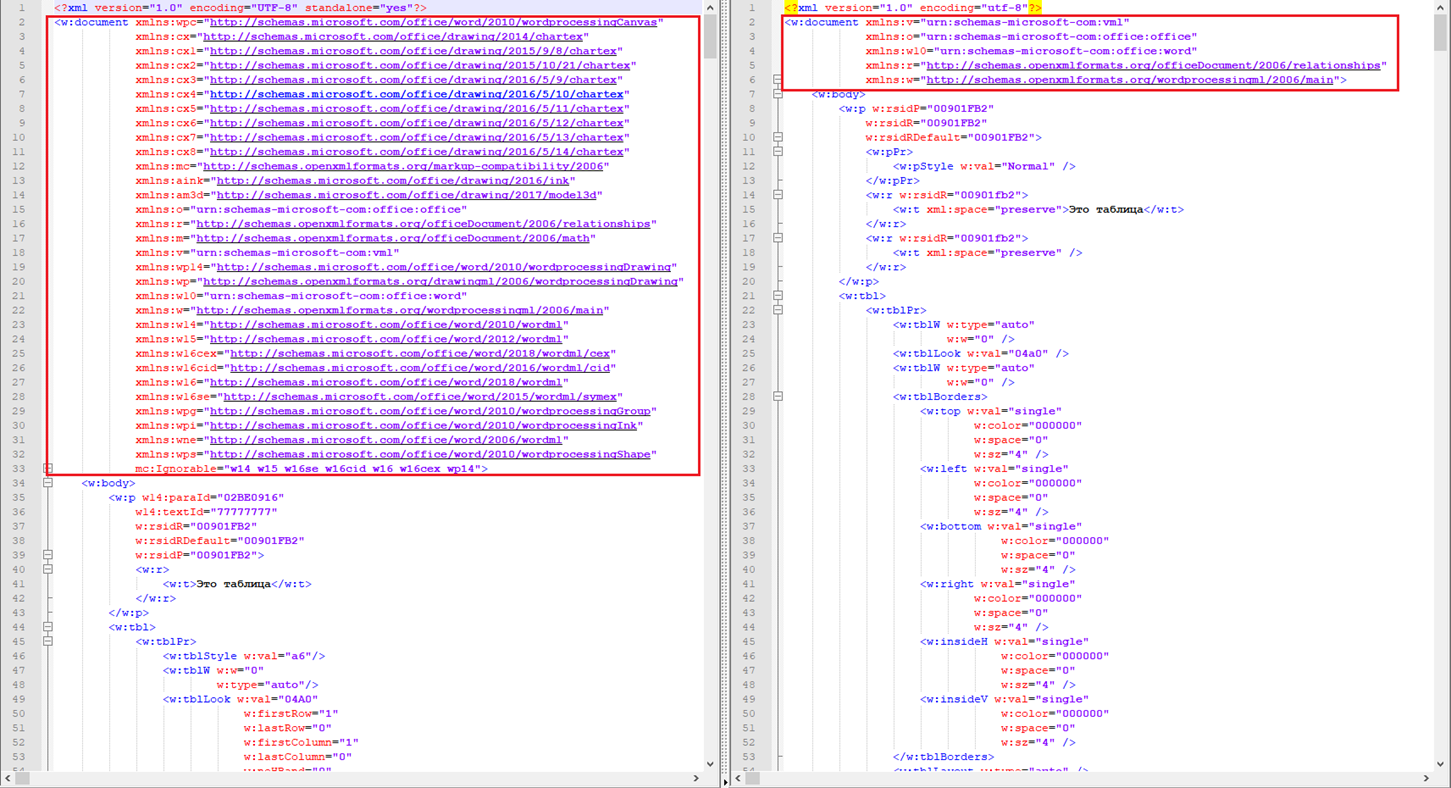
Налицо явное отличие в атрибутах тега “w:document” , но этим отличия не заканчиваются. Всю "мощь" библиотеки мы ощутим, когда захотим обработать списки и при этом:
- a. Сохранить их нумерацию
- b. Не потерять структуру вложенности
- c. Отделить один список от другого
Давайте сравним файлы document.xml для вот этого списка:
1.1 Первый.Первый 1.2 Первый.Второй 1.2.1 Первый.Второй.Первый 1.2.2 Первый.Второй.Второй Какая-то строчка 1.2.3 Первый.Второй.Третий 2. Второй 2.1 Второй.ПервыйВот так будет выглядеть .xml для первого элемента списка.
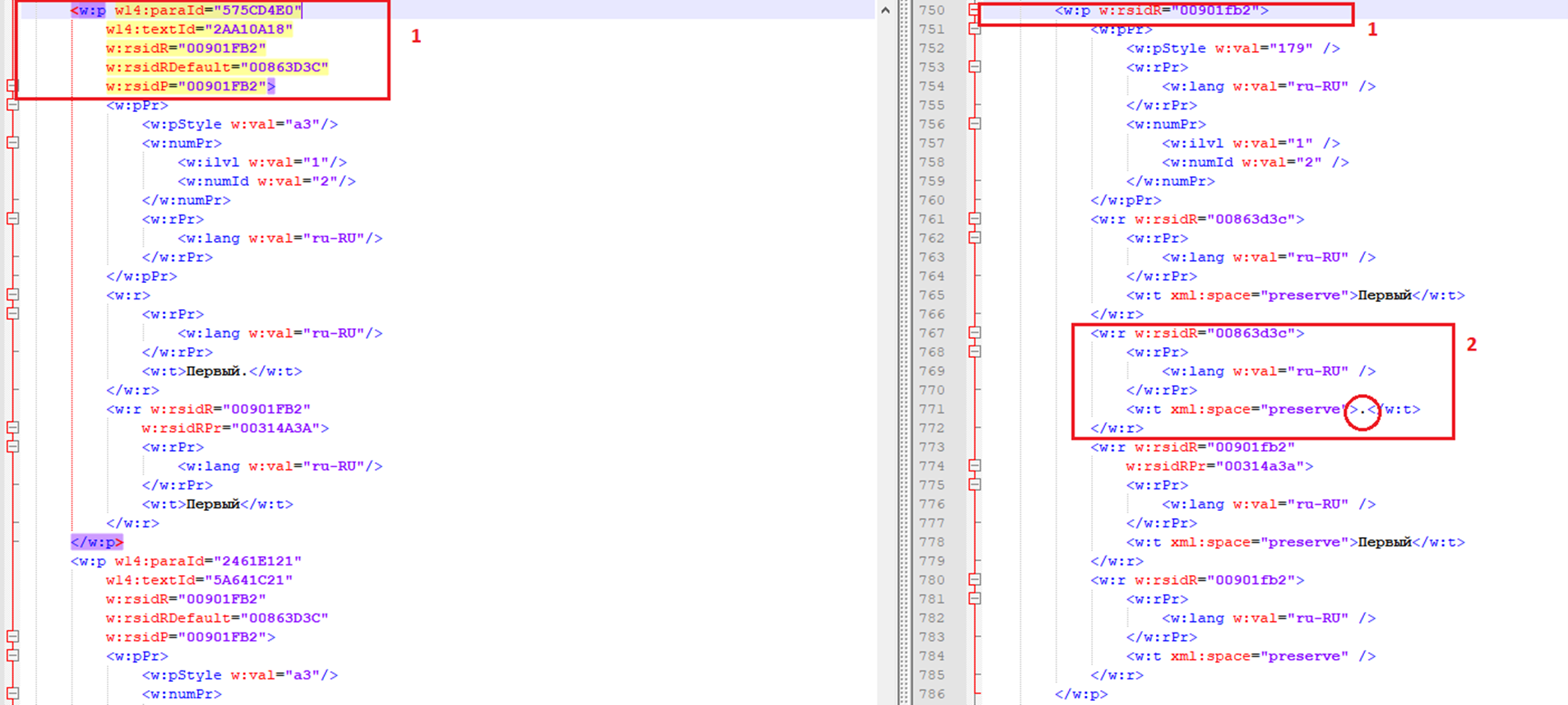
-Во-первых, мы видим, что сама структура документов несколько отличается (например, точка внутри строк рассматривается как отдельный элемент, что, как оказалось, совсем не страшно). -Во-вторых, у тегов остался только один атрибут ( w:rsidR ), а вот w:rsidR , w14:textId , w:rsidRDefault , w:paraId и w:rsidP пропали. Все эти особенности приводят к тому, что наш класс-конвертер DocxToXml (про него подробно можно почитать здесь) подавится и поднимет лапки вверх с ошибкой NullReferenceException , что указывает на отсутствие индексирования параграфов внутри документа.
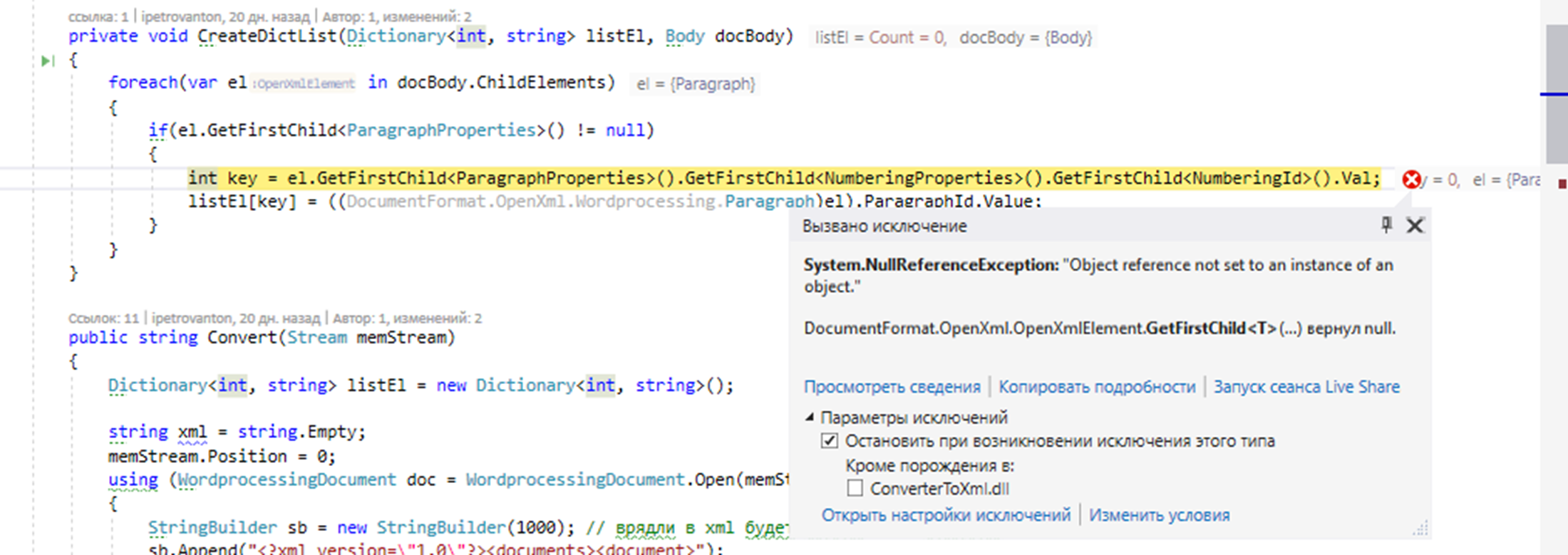
Вместе с тем, если мы попытаемся такой файл отрыть в Word, то увидим, что все хорошо отображается, а таблицы и списки покоятся на своих местах! Магия!
В общем, когда в поисках решения я потратил N часов на чтение документации, мои красные от дебагера глаза омылись горькими слезами, а один лишь запах кофе стремился показать коллегам мой дневной рацион, решение было найдено!
Исходя из документации к формату doc и алгоритмов работы b2xtranslator, можно сделать вывод, что исторически в бинарных офисных текстовых документах отсутствовала индексация по параграфам*. Возникает задача расставить необходимые теги в нужных местах.
xmlns:wp14="http://schemas.microsoft.com/office/word/2010/wordprocessingDrawing"Теперь давайте заставим b2xtranslator добавлять это пространство имен и идентификатор каждому параграфу. Для этого в файле “~b2xtranslatorCommonOpenXmlLibContentTypes.cs” после 113 строки добавим вот эту строчку:
public const string WordprocessingML2010 = "http://schemas.microsoft.com/office/word/2010/wordml";Кстати, если посмотрите на комментарии в коде, то увидите, что в этом блоке как раз располагаются поддерживаемые пространства имен для вордовых документов:

Далее наша задача – заставить библиотеку вставлять в начало файла ссылку на данное пространство имен. Для этого в файле “~b2xtranslatorDocWordprocessingMLMappingMainDocumentMapping.cs” в 24 строке вставим код:
this._writer.WriteAttributeString("xmlns", "w14", null, OpenXmlNamespaces.WordprocessingML2010);Разработчики библиотеки также позаботились о документации:

Теперь дело за малым – заставить b2xtranslator индексировать параграфы. В качестве индексов предлагаю использовать рандомно сгенерированные GUID – может быть, это несколько тяжеловато, но зато надежно!

Переходим в файл “~b2xtranslatorDocWordprocessingMLMappingDocumentMapping.cs” и в 504 и 505 строки вставляем вот этот код:
this._writer.WriteAttributeString("w14", "paraId", OpenXmlNamespaces.WordprocessingML2010, Guid.NewGuid().ToString()); this._writer.WriteAttributeString("w14", "textId", OpenXmlNamespaces.WordprocessingML2010, "77777777");Что касается второй строчки, в которой мы добавляем каждому тегу параграфа атрибут w14:textId = "77777777" , то тут можно лишь сказать, что без этого атрибута ничего работать не будет. Для пытливых умов вот ссылка на документацию.
Если серьезно, то, как я понимаю, атрибут используется, когда текст разделен на разные блоки, внутри которых происходит индексация тегов, которые могут иметь одинаковый Id внутри одного документа. Видимо, для этих случаев используется дополнительная индексация текстовых блоков. Однако, так как мы используем GUID, который в несколько раз больше индексов, используемых в вордовских документах по умолчанию, то генерацией отдельных индексов для текстовых блоков можно и пренебречь.

В заключение, если у вас на проекте есть возможность воспользоваться платным надежным софтом, то этот путь скорее всего не для вас. Однако же, если вы энтузиаст, пишете свой pet-проект и уважительно относитесь к авторским правам, а также если ваш проект находится в стадии прототипирования и пока не готов к покупке дорогостоящих лицензий, а разработку продолжать надо, то, мне кажется, этот вариант может вам очень даже подойти! Тем более, что у вас есть возможность воспользоваться готовым решением и не заливать свои краснющие зенки визином, изучая документацию и особенности работы некоторых, на первый взгляд, сомнительных решений.