4.5 Оценок: 863 (Ваша: )
4.5 Оценок: 863 (Ваша: )
Планируете перевести на цифровой формат значимые документы? Вам нужна программа для сканирования. На рынке представлено множество как платных, так и бесплатных приложений, которые помогут настроить процессы оцифровки, обработать документы и выполнить оптическое распознавание текста. В этой статье мы рассмотрим 10 лучших программных решений.
Как редактировать отсканированные PDF файлы
Приложение PDF Commander идеально подходит для редактирования сканированных документов, позволяя объединять страницы в многостраничный PDF, конвертировать его в различные форматы и изменять содержимое страниц: добавлять изображения, электронные подписи и штампы.
Кроме того, программа дает возможность упорядочить страницы, удалять ненужные и добавлять новые, устанавливать пароль для доступа или редактирования. Вы можете извлечь текст и изображения из документа, а также отправить информацию на печать с возможностью настройки параметров вывода.
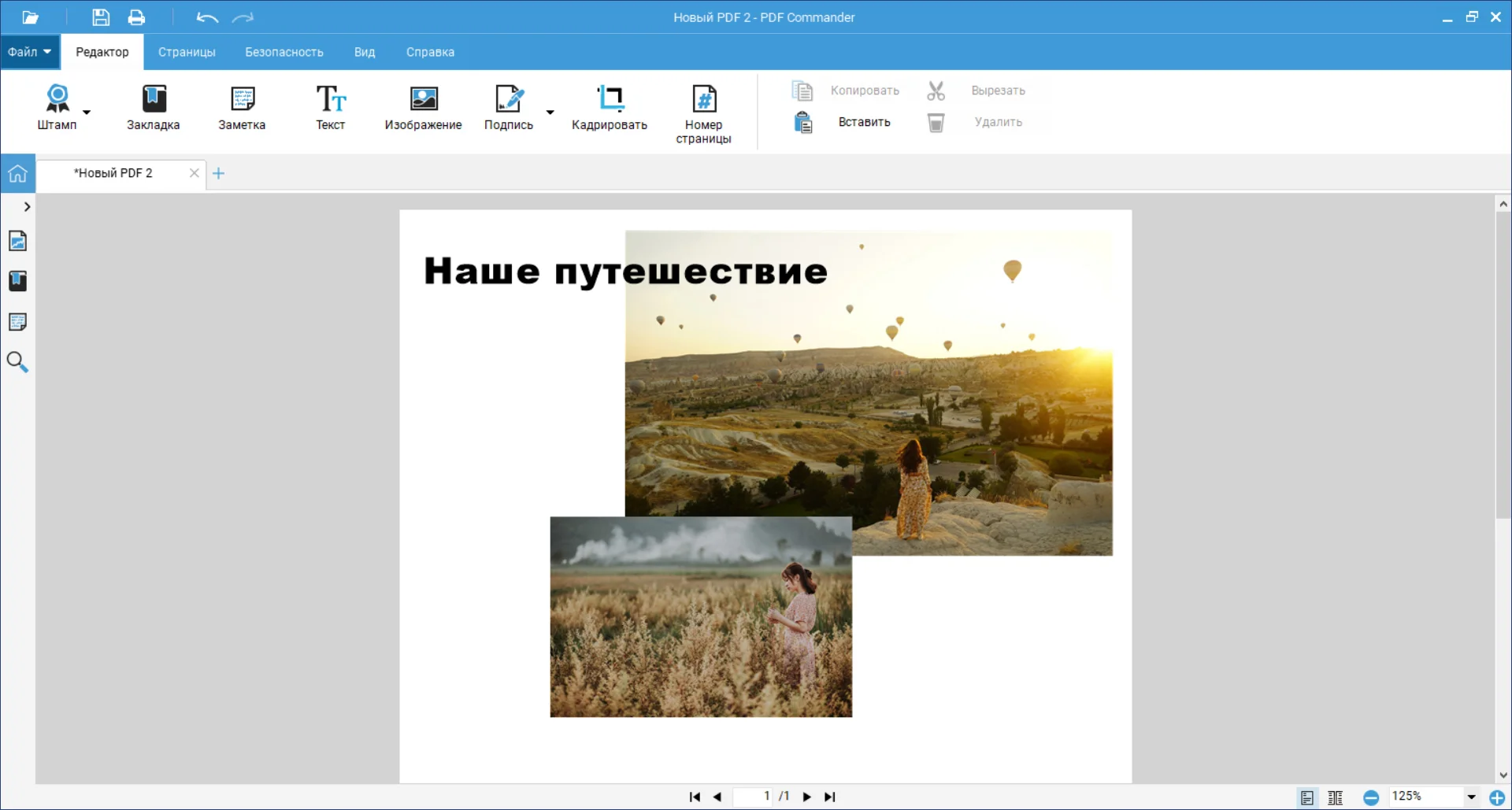
Программа имеет удобный интерфейс на русском языке и подходит начинающим. Вы можете установить ее на Windows 11, 10, 8, 7 и сразу же приступить к редактированию!
Загрузите PDF Commander прямо в данный момент:
ТОП-10 программ, чтобы сканировать документы на компьютер за считанные минуты
Для настройки процесса сканирования рекомендуем использовать специализированные программы. Они обеспечивают возможность подключения к большинству моделей принтеров и изменения установок вывода. Некоторые приложения предлагают функции оптического распознавания текста и редактирования страниц.
ABBYY FineReader
Программное обеспечение для оцифровки материалов, извлечения текста и графических элементов. Оно также позволяет редактировать медиафайлы, устанавливать защиту и открывать доступ для совместного использования. Вы можете применить софт для изменения существующих PDF или создания их из сканов страниц.
Новая версия ABBYY FineReader оснащена функцией распознавания текста с использованием технологий искусственного интеллекта. Вы можете бесплатно скачать программу и воспользоваться пробным периодом. После этого потребуется оформить бессрочную лицензию или подписку на один год.
К недостаткам можно отнести достаточно высокую цену: базовый пакет, который предоставляет возможность просмотра, сканирования и редактирования информации, стоит 8990 рублей. Корпоративная версия будет стоить компании 48 990 рублей.
OCR CuneiForm
OCR CuneiForm — это программа, предназначенная для распознавания текста на сканированных или сфотографированных документах. С её помощью можно преобразовать изображения в редактируемые текстовые файлы и сохранять их в форматах Word, Excel и других. Данная система поддерживает распознавание текстов на английском, русском, немецком, украинском языках и многих других.
Недостатком является отсутствие поддержки от разработчика. Последнее обновление вышло в 2011 году. Сейчас установить ПО на Виндовс можно только со сторонних сайтов. Открытую версию для Linux можно использовать в качестве библиотеки.
RiDoc
RiDoc подходит для оцифровки медиаданных, а также определения символов. RiDoc работает с большинством TWAIN или WIA принтеров и сканеров. У вас будет возможность сохранить сканы в различных медиаформатах: BMP, JPG, PNG, Word. Затем можно отправить их по электронной почте или загрузить в облачное хранилище.
Из минусов отметим короткий пробный период: ПО можно использовать бесплатно в течение 30 дней. Затем на результате будет размещен водяной знак. Для снятия ограничений потребуется приобрести лицензию за 450 рублей.
VueScan
VueScan — это простая программа для сканирования документов на компьютер и расширения функционала планшетных и пленочных сканеров. Она позволяет получить четкие изображения с точными и сбалансированными цветами, а также содержит опции для коррекции картинок. Программное обеспечение сканирует данные и превращает их в многостраничные ПДФ или создает отдельные файлы JPEG и TIFF. Также оно предлагает функцию для оптического распознавания слов. Софт содержит инструменты для пакетной обработки и совместим с большим количеством устройств.
Из недостатков можно отметить возможность использовать ПО бесплатно только в течение пробного периода. Лицензионный пакет стоит 2 тысячи рублей.
Scanitto Pro
Scanitto Pro предназначен для перевода бумажных носителей в различные цифровые форматы. С его помощью можно создать многостраничные файлы или сохранить отдельные листы. Также он содержит инструменты для распознавания слов, которые позволяют редактировать текст со сканов.
Из минусов можно отметить ограниченный пробный период, который действует 30 дней. Затем нужно купить ПО за 598,80 руб.
PaperScan
PaperScan — это софт для сканирования, позволяющий обрабатывать, комментировать, сжимать и сохранять изображения в виде многостраничных файлов. Пользователю также доступны инструменты для обработки изображений: автоматическое выравнивание, поворот, удаление границ и перфорированных отверстий, перевод негатива, настройка цвета, эффекты, кадрирование и другие. Также здесь вас ждут функции пакетной обработки, шифрования и установки пароля на чтение, двустороннего копирования, автоматического удаления пустых страниц и режим быстрого сканирования.
Недостатком является отсутствие русскоязычного меню. Также для использования ПО потребуется приобрести лицензию за 79 долларов.
Readiris Pro
Readiris Pro — это программа, совместимая с операционными системами Windows и Mac. Она позволяет преобразовывать сканированные документы в формат PDF. Вы сможете не только просматривать эти файлы, но и редактировать их благодаря функции оптического распознавания символов, которая поддерживает более 100 языков. Кроме того, Readiris предоставляет облачное хранилище. Готовую работу можно экспортировать в облако и использовать для совместного доступа или редактирования данных в пути.
Минусом софта является высокая стоимость: 99 долларов. Также программное обеспечение совершает ошибки в распознавании слов, поэтому перед сохранением окончательного итога потребуется вычитка и редактура.
NAPS2
NAPS2 подходит для сканирования, т.к. ориентированно на простоту и удобство использования. У вас будет возможность преобразовать бумажные носители в цифровой контент с помощью WIA- и TWAIN-совместимых аппаратов и сохранить их в TIFF, JPEG, PNG и других медиаформатах. NAPS2 полностью бесплатен и имеет открытый исходный код.
Редактор позволяет выбрать или создать свои профили сканирования: указать устройство, источник бумаги, размер, глубину цвета, разрешение и т.д. Результат импортируются непосредственно в NAPS2, и затем вы можете сохранить его как изображение или ПДФ.
Недостатком является отсутствие поддержки Виндовс XP и Vista. Также для работы требуется .NET Framework 4.0 или выше.
EasyScan
EasyScan — это инструмент для оцифровки и расширения функционала подключенного сканирующего оборудования. EasyScan обрабатывает материал с различной глубиной цвета, а затем конвертирует его перед выводом в подходящем расширение.
Минусом софта является отсутствие поддержки разработчика. Он не обновлялся с 2011 года и его можно загрузить только со сторонних онлайн-сервисов. Интерфейс редактора на английском языке и может показаться сложным начинающим.
WinScan2PDF
WinScan2PDF — это бесплатное приложение, способное сканировать документы и сохранять их на компьютер в PDF с помощью любого установленного сканирующего оборудования. Оно поддерживает большое количество моделей сканирующих устройств и предлагает удобное русскоязычное меню. Программа не требует установки и предлагает portable-версию, которая весит всего 40 КБ. Она также не требовательна к ресурсам компьютера и может быстро работать на старых ПК и ноутбуках.
Недостатком софта является экспорт в одном формате. Также ПО не имеет функции для коррекции контента и добавления графических элементов.
Лучшие бесплатные OCR-сервисы для распознавания и конвертации PDF
Привет всем! Я расскажу о сервисах для распознавания текста или OCR. Считайте это небольшим рейтингом лучших OCR-утилит.

Оптическое распознавание символов (OCR — Optical Character Recognition) представляет собой процесс цифрового или механического преобразования изображений или текстов, таких как сканированные документы, фотографии и так далее.
Я испытаю следующие программы и сервисы:
Чтобы результат был наглядным и достоверным, нужно протестировать. Для этого я подготовил специальные документы:
Adobe Acrobat Pro
Я попробую сравнить качество распознавания при конвертировании в редактируемый формат между бесплатными сервисами и эталоном — Adobe Acrobat DC.
Adobe Acrobat DC идёт первым как эталон, созданный для одной задачи — для работы с pdf-файлами.
Простой файл с текстовым слоем:

Ожидаемо. Никаких трудностей. Полная конвертация в редактируемый формат. Изображение по центре осталось нетронутым, но это невеликая проблема, можно подписать или обработать в Paint.
Простой файл без текстового слоя:

Нестандартный шрифт не распознался, но мелкий шрифт под звёздочкой распознался достаточно хорошо. Ещё пару букв пропустил, но допустимая погрешность для последующего ручного редактирования.
Сложный файл с непостоянным текстовым слоем:

Способ выражения. Исход не удивил, качество оставляет желать лучшего, так как файл достаточно запутанный. Тем не менее, его можно отредактировать, что лучше, чем полностью игнорировать.
Почему я не взял на тест больше программ для ПК? А их нет. Существует несколько простых программ, которые распознают только изображения или устанавливают на компьютер мусор. Я пробовал: Free OCR, Simple OCR, CuneiForm OCR, Freemore OCR. Вторая категория — это титаны вроде Abbyy или Adobe, которых мы стараемся избежать в этой статье.
Итак, перейдём к онлайн-сервисам.
PDF24 tools
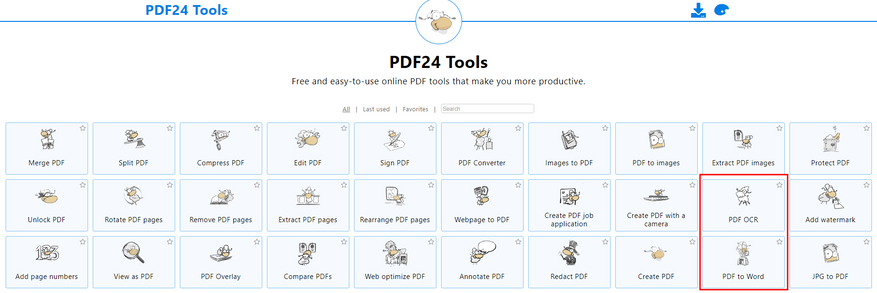
PDF24 tools — многогранный сервис. Он может распознать текст в PDF, но в результате всё равно выдаст PDF. На наше счастье среди утилит этого сайта есть и конвертер в Word. Они даже расположены рядом.
Простой файл с текстовым слоем:

Получилось очень плохо, но текст типа сохранён полностью. Изображение вырезано и половина страницы пустая. Ладно, сочтём, что так и должно быть.
Простой файл без текстового слоя:
С задачей сервис не справился. После распознавания и конвертации в ворд, я увидел пустой лист.
Сложный файл с непостоянным текстовым слоем:
Результат оказался таким же — пустой лист. Но сервис предлагает три режима конвертации:
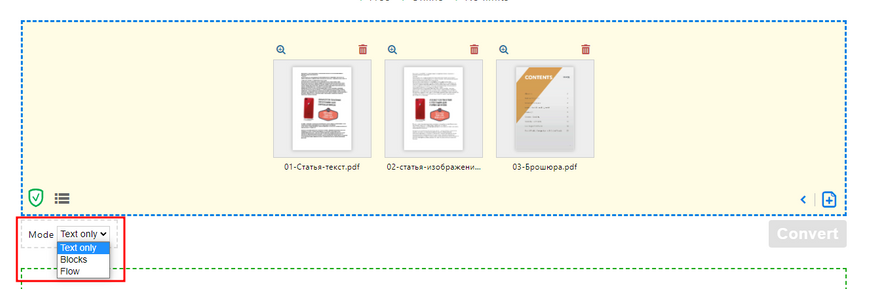
Я протестировал все три варианта, и третий режим "только текст" показал наилучший результат:

Распознался даже сложный шрифт!
Брошюра тоже распозналась, но легче мне от этого не стало:

Спорный сервис. Конвертирует и распознаёт быстро и удобно, много разных утилит. Пусть будет, конечно, на крайняк покатит.
NewOCR
NewOCR — нашёл в одной из статей про лучшие сервисы распознавания символов на просторах интернета. Говорят, что сервис хороший.
Простой файл с текстовым слоем:
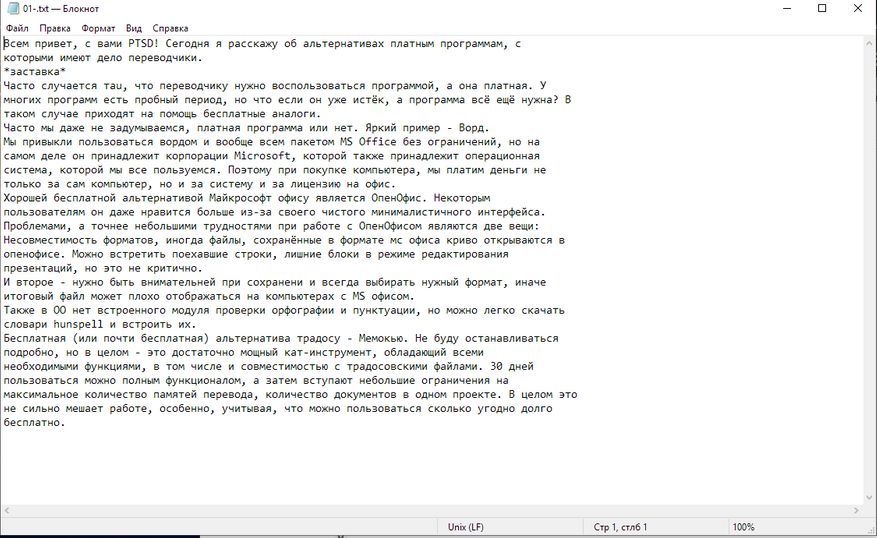
Текст распозанёт хорошо, но предлагает выбрать только формат .txt, не распознаёт картинку и даже не пытается сохранить форматирование.
Простой файл без текстового слоя:

Неплохо распознал основной язык — русский, но ужасно справился с английским. Вся латиница превратилась в какую-то кашу. С другой стороны распознать получилось даже нестандартный шрифт с картинки. Не без ошибок, нор всё же. А ещё удалось получить формат Word.
От чего это зависит — не знаю.
Компонент с переменным текстовым содержимым:
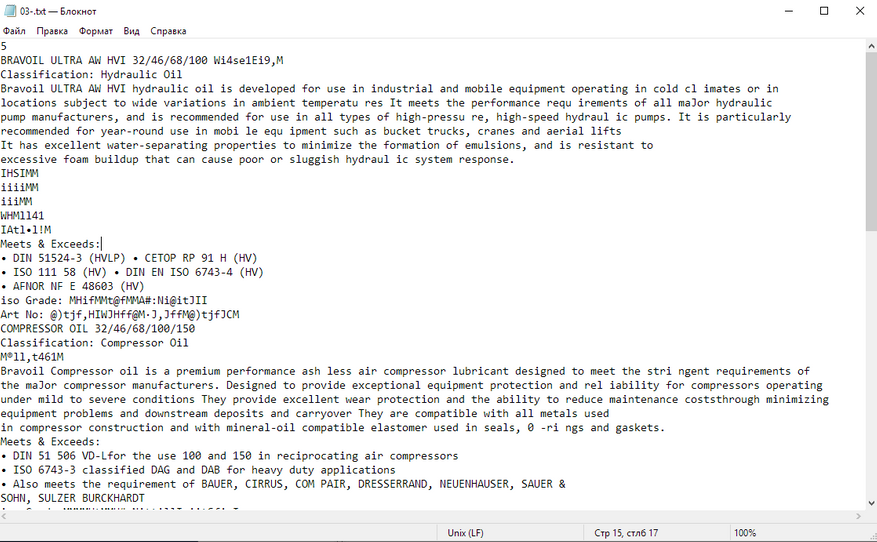
Брошюра тоже распозналась косячно. Вместо многих символов ужасные кракозябры, слова собрались в кашу, формат только .txt. Зачем мне нужно вот это? Легче отредактировать скриншоты в paint, чем так.
Сервис неплохо справляется с распознаванием текста, но что-нибудь сложнее, чем абзацы текста ему не под силу. Если в тексте встречается несколько языков, то один из них обязательно будет воспринят неправильно. Даже если указать два языка в поле перед распознанием. Про форматирование можно забыть, его здесь не будет.
А ещё мне не понравилось, что каждую страницу многостраничного документа придётся распознавать и скачивать отдельно. Документ на 50 страниц? Простите, но придётся выкачивать по одной странице за раз. А ещё придётся подождать 5 секунд перед распознанием очередной страницы. Не больше ни меньше.
Если попытаетесь распознать быстрее, получите ошибку. А ещё не всегда с первого раза точно прицеливается в страницу, иногда выхватывает маленький фрагмент страницы и пытается его распознать.
Img2txt
Сервис Img2txt. Нашёл его где-то на просторах интернета в комментариях к статье о лучших сервисах.
Простой файл с текстовым слоем:
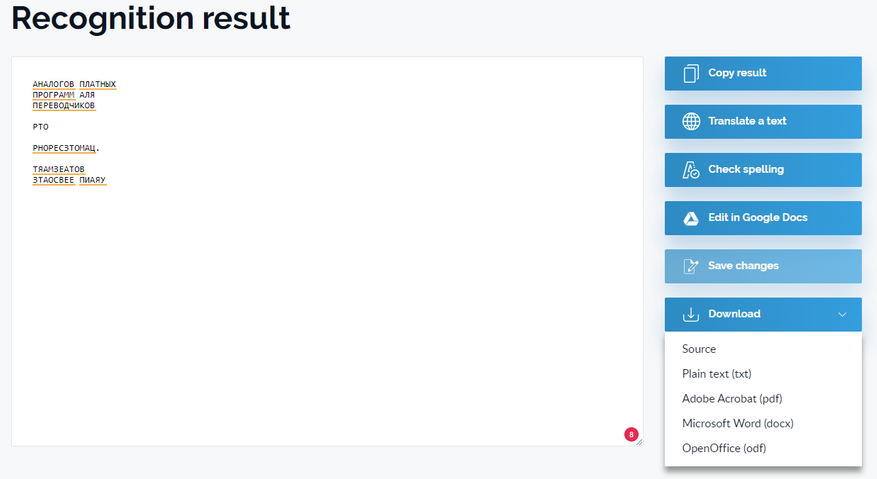
Крупный текст распознал, мелкий превратил в кашу. Решил, забить на текстовый слой и распознал только картинку. Странное решение. Зато предлагает много форматов.
Простой файл без текстового слоя:
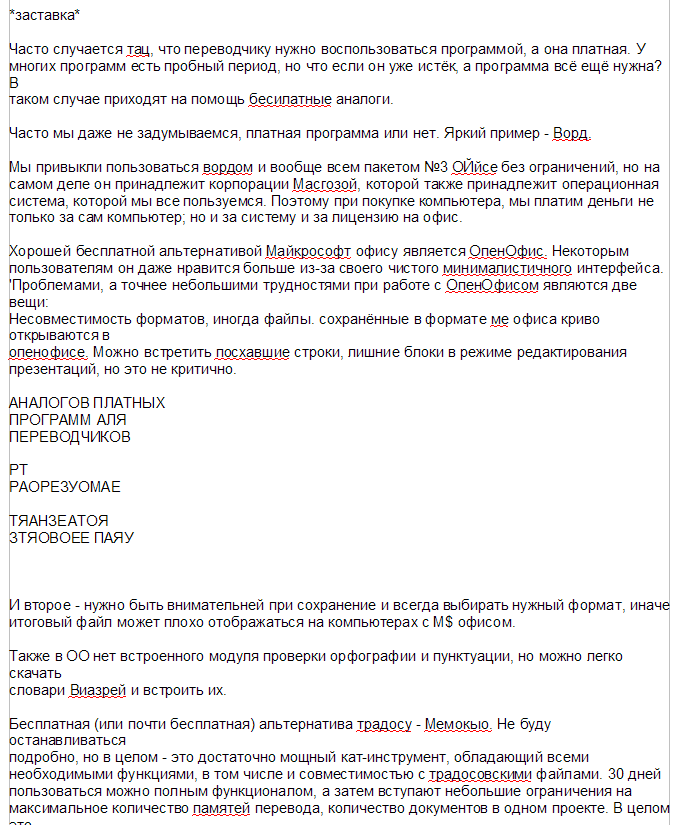
Не сказать, что плохо, но и не сказать, что хорошо. Некоторые буквы перепутал, латиницу не распознал. Но по крайней мере можно скачать в вордовском формате.
Комплексный документ с переменным текстовым содержимым:
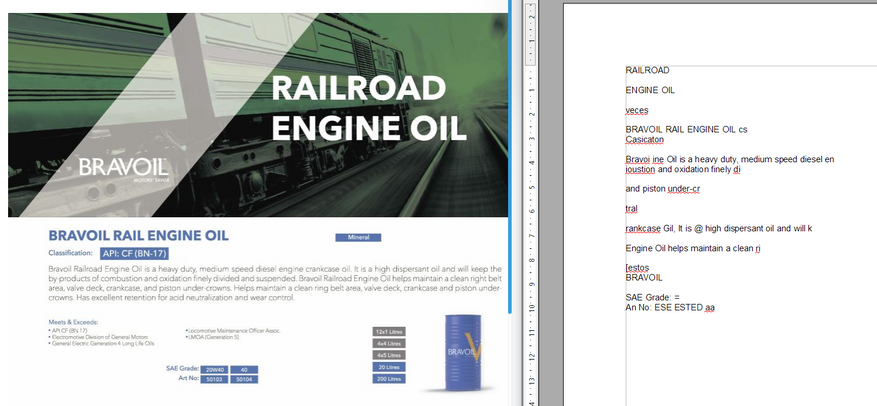
Куцый результат. Распозналось плохо, большая часть текста пропущена, слова в кашу превратились. Получилась бесполезная белиберда.
Ещё один сервис, который распознаёт неплохо простые документы с большими абзацами текста. Раздражает, что сначала нужно загрузить файл, выбрать для него язык, потом файл обработается сервером, нужно снова выбрать для него язык и запустить распознавание. Я как-то ожидал, что загружая я уже достаточно чётко выражаю намерение распознать файл.
Ещё одна беда — это постраничное распознавание. Как и в случае с NewOCR каждая страница распознаётся отдельно, скачивается отдельным документом. Только тут ещё необходимо для каждой новой страницы повторно выбирать язык.
А ещё это единственный сервис с ограничением размера файла. Максимум — 8 мб.
Online OCR
Online OCR — сервис с самым непримечательным названием. Я упоминал этот сервис в статье про 8 бесплатных аналогов платных программ.
Простой файл с текстовым слоем:

Ого. Результат удивляет. Почти идеальный. Мало того, что распознание прошло почти мгновенно, так ещё и латиница распозналась там, где надо. Даже мои опечатки были распознаны правильно. То что текст вокруг картинки — это ерунда.
Чуть-чуть не дотянул до уровня Adobe.
Простой файл без текстового слоя:

Попали в цель снова! На этот раз было больше ошибок, но итог неплохой. По крайней мере, изображение осталось, и часть мелкого текста с него удалось идентифицировать.
Сложный файл с непостоянным текстовым слоем:

Ух ты! Сервис справился с распознаванием и этого документа! Удивительно, но факт. Есть некоторые недочёты, но это очень хороший результат. С редактированием такого файла в ворде придётся очень сильно помучиться, зато распознаны все таблички, большинство надписей.
Если в ваши обязанности не входит вёрстка, то это именно то, что нужно.
Я бы назвал это самым большим успехом. Даже Adobe по сравнению с этим меркнет:

Это лучший сервис! К сожалению, без регистрации он не даст распознать PDF больше 15 страниц, большие изображения, ZIP-архивы и ещё что-то. Но после регистрации сервис даёт только 50 бесплатных страниц.
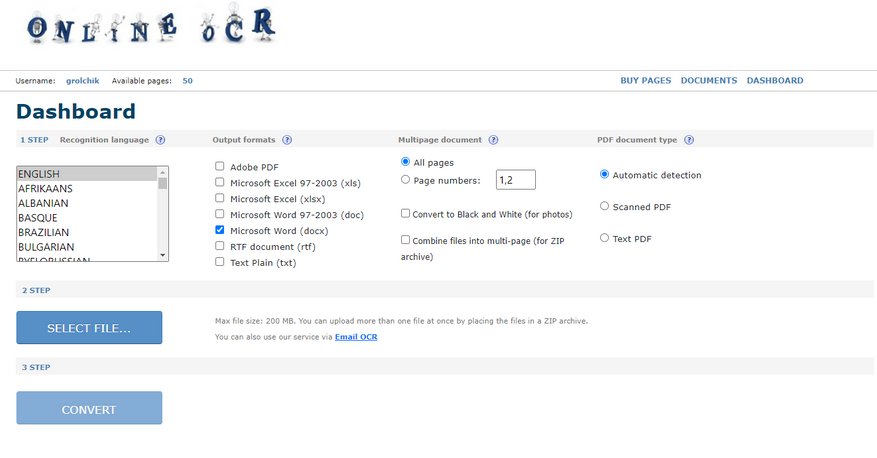
Я слышу слово "абьюз" или мне кажется? Раскрою секрет, как сделать сервис абсолютно бесплатным. Создатели сайта не придумали подтверждение почты при регистрации. Можно указать любой вымышленный адрес. Как только заканчиваются страницы, переезжаем на новый аккаунт и пользуемся 50 бесплатными.
Забавно получается.
Читайте другие статьи переводческого цикла: